Text2Stereo: Repurposing Stable Diffusion for Stereo Generation with Consistency Rewards
CVPR 2025 Workshop on Computer Vision for Mixed Reality (CV4MR)
-
Aakash Garg
Texas A&M University -
Libing Zeng
Texas A&M University -
Andrii Tsarov
Leia Inc. -
Nima Khademi Kalantari
Texas A&M University

Abstract

In this paper, we propose a novel diffusion-based approach to generate stereo images given a text prompt. Since stereo image datasets with large baselines are scarce, training a diffusion model from scratch is not feasible. Therefore, we propose leveraging the strong priors learned by Stable Diffusion and fine-tuning it on stereo image datasets to adapt it to the task of stereo generation. To improve stereo consistency and text-to-image alignment, we further tune the model using prompt alignment and our proposed stereo consistency reward functions. Comprehensive experiments demonstrate the superiority of our approach in generating high-quality stereo images across diverse scenarios, outperforming existing methods.
Results

There are glowing mushrooms lighting up the depths of an underground forest

There are lanterns floating in the sky over a tranquil lake
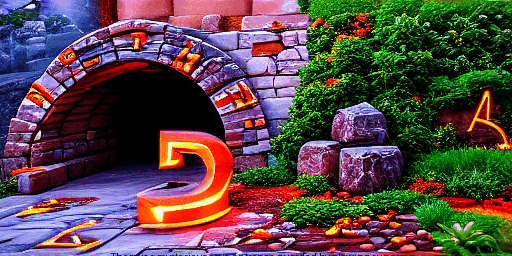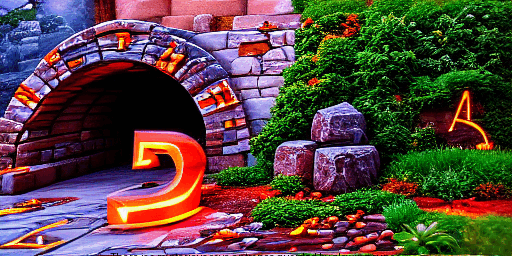
There is a mysterious cave entrace guarded by glowing runes

There are tall sunflowers swaying in a gentle summer breeze
BibTeX
@inproceedings{garg2025text2stereo,
title = {Text2Stereo: Repurposing Stable Diffusion for Stereo Generation with Consistency Rewards},
author = {Garg, Aakash and Zeng, Libing and Tsarov, Andrii and Khademi Kalantari, Nima},
booktitle = {CVPR 2025 Workshop on Computer Vision for Mixed Reality (CV4MR)},
year = {2025}
}
Acknowledgements
The project was funded by Leia Inc. (contract \#415290). Portions of this research were conducted with the advanced computing resources provided by Texas A\&M High Performance Research Computing. We express our gratitude to the anonymous reviewers for their insightful comments and suggestions.
The website template was borrowed from Michael Gharbi.