|
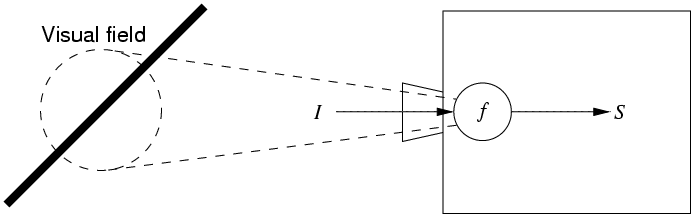
The basic question addressed in the above paper is this. In a visual agent below (the box on the right), if the only information available about the visual scene is S, the output generated by a filter (or a feature detector if you will) f, how can the agent know if S was due to an oriented bar at 45° or some other angle, or for that matter if it was visual at all? Note that inside the agent, the environmental stimulus I is not available, and let us assume that the agent is ignorant of the particular functional form of f.
The situation depicted here is identical to the problem faced by neurons in the brain, because the only language they speak is in spikes, and they do not have direct access to the external stimuli. How then can it be possible, in principle, for such an agent (or the brain) to learn what S means?
Thus, the only solution to this problem may be to allow the agent to generate action, e.g., gazing at different locations of the input by actively moving around its visual field. The key insight here is that the kind of motion that keeps the state S invariant over time during the execution of action exactly reflects the oriented property of the input stimulus I (and hence that of the filter f). For example, in Figure 1, the only motion that can keep the state S invariant (i.e., fixed at 1) is to move the visual field back and forth in the 45° diagonal, and such a motion exactly reflects the stimulus property encoded by f. Thus, even without any knowledge about I nor about f, the agent can learn (in an unsupervised manner) what its internal state S means through action that maintains invariance in S. Based on the above, two points become clear: (1) voluntary action can provide meaning to one's internal perceptual state, and (2) maintained invariance in the internal perceptual state can serve as a criterion (or an objective) for learning the appropriate action sequence.
The following Java applet demonstrates the use of such an invariance criterion. To run an experiment, follow these instructions:
The four circles at the bottom are the sensory state of the four orientation filters, each sensitive to 0°, 90°, 45°, and 135°, from the left to the right. When you run the simulation, initially several filters will turn on (white), but quickly only one filter will be turned on continuously. The animation in the center shows the action generated by the SIDA agent (blue disc is the current location of the gaze), and you will be able to see that the motion exactly reflects the filter's orientation preference. Thus, this small demo shows that if you're caught in a room as shown in Figure 1, you may be able to figure out what the filter output S means through sensory-invariance driven action.
Source: Sida.java, available under GNU Public License.
Last updated: Mon Sep 27 18:11:24 CDT 2004