Text: The person is doing backflip.

1.DDP Training Accelerate: DDP (Distributed Data Parallel) training is a parallelization technique commonly used in deep learning to train large neural networks efficiently across multiple GPUs or distributed computing environments. It is designed to address the challenges of training deep neural networks with massive amounts of data and complex architectures. I add it to accelerate the training process.
2.In-the-wild Video Testing: Original method required delicate camera to capture and annotated data. I use a in the wild video from internet and cooperate with other sota method to get the smpl and mask annotation to enable the method to use at random in-the-wild videos.
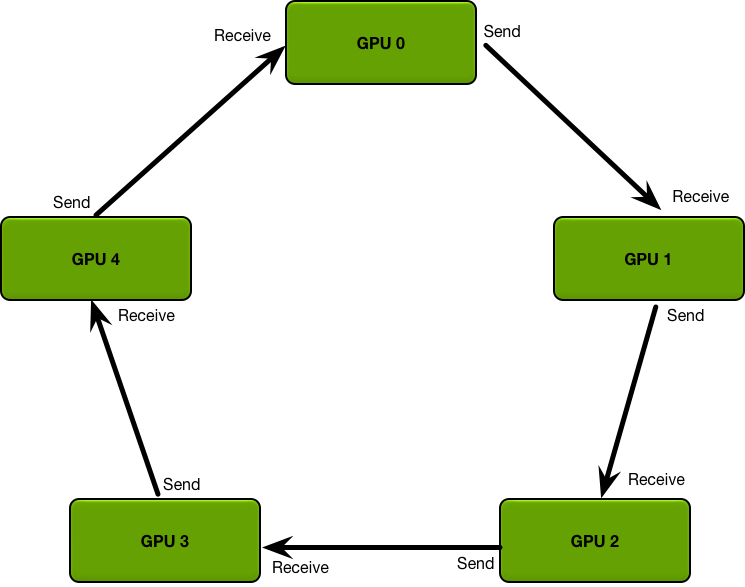
A ring allreduce is an algorithm for which the communication cost is constant and independent of the number of GPUs in the system, and is determined solely by the slowest connection between GPUs in the system; in fact, if you only consider bandwidth as a factor in your communication cost (and ignore latency), the ring allreduce is an optimal communication algorithm. (This is a good estimate for communication cost when your model is large, and you need to send large amounts of data a small number of times.)
The algorithm proceeds in two steps: first, a scatter-reduce, and then, an allgather. In the scatter-reduce step, the GPUs will exchange data such that every GPU ends up with a chunk of the final result. In the allgather step, the GPUs will exchange those chunks such that all GPUs end up with the complete final result.
*The video is randomly selected from internet.
For in-the-wild video, I use Pare to estimate the SMPL annotation of the video, and use RVM to get the mask of the person. After getting these annotation, I wrote some scripts to process them and access to the original codes to train the model.
Text: The person is doing backflip.
Text: A person punches in a manner consistent with martial arts.
Text: A person first kick something with his left leg and then right leg.
Text: A person run in a circle.
*We use MDM model to generate poses from text.
*We borrow music poses from AIST++ dataset.
[1]Yu, Zhengming, et al. "MonoHuman: Animatable Human Neural Field from Monocular Video." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.