Visual information workspaces for analysis allow users to collect, organize, and interpret information during knowledge-intensive tasks. Users non-verbally express formative interpretations through visual attributes and spatial layout. Over time, these visual codings evolve into visual languages categorizing and expressing relationships among information objects. To better support this process of emergence, the Visual Knowledge Builder extends prior work on visual information workspaces. Similar to prior systems, users manipulate visual symbols representing information objects in a hierarchy of two-dimensional workspaces called collections. Prior experience led to extensions to the visual and semantic representations and the recognition of implicit object types. The Visual Knowledge Builder includes an embedded history mechanism for returning to prior states of the information space and replaying the unfolding interpretation. The Visual Knowledge Builder has been used for both short-term and long-term tasks, identifying potential enhancements and refining our understanding of the effects of visual workspaces on analytic practice.
Information workspaces, knowledge building, analysis, interpretation, embedded history, emergent structure, visual languages, constructive ambiguity
When confronted with an information need, many people now go to their connection to the Internet first rather than their television, radio, newspaper, or books. The Internet’s navigation and search allow the interactive browsing and selection of information. This interactivity, combined with differences in the quality and quantity of information, has lead to changes in the practice of information tasks.
One effect of the growth of the Internet as a mechanism for information distribution is that people have easy access to a greater variety of information than ever before. It is now common to find confusing or contradictory information for any complex question. As an example, take the simple task of using AltaVista to search for the “capital of Kentucky.” Three of the top four pages are for Berea rather than Frankfort. By reading closer we learn Berea is either “the antique capital” or “the folk arts and crafts capital” of Kentucky depending on the source. People now can (and frequently need to) gather corroborating evidence for their information tasks. Indeed, many Internet sites act only as a clearinghouse for getting to other sites which contain information on a particular topic.
The nature of the information sources has changed as well – many sources of information are unedited or unmonitored, imposing the responsibility of deciding what to believe and what not to believe on the reader. Of course, this is true in print but traditional document genres help – flyers on a bulletin board are easily distinguishable from a newspaper, magazine, or tabloid. Also, most people have quick access to fewer sources in print and those are easier to distinguish. With the Internet, individuals can construct professional-looking information repositories.
Information tasks vary greatly in complexity. Finding the current price of a stock, the score of a ballgame, or the location of a conference hotel are short-term tasks where searching for or navigating to the information source dominates the effort leading to the completion of the task. On the other hand, when evaluating the state of a technology or predicting the long-term value of a company, searching for sources of information becomes a much smaller portion of the information task. In these cases, the effort involves deciding what information is needed, what information sources are believable, and how the various pieces of information fit together. This is the process of interpretation and analysis.
The growing use of the Internet as an information source and the nature of Internet information sources leads to a greater need for tools supporting analysis. This paper discusses the design of and experiences with one such tool. The next section characterizes analytic workspaces. After this, we describe the Visual Knowledge Builder and how it is designed based on experiences with prior information workspaces. Finally, we present observations on the use of the Visual Knowledge Builder for long-term and short-term tasks and conclusions based on these experiences.
Analysis includes the collection, prioritization, evaluation, and interpretation of information. In this section, we discuss experiences with visual information workspaces and their interaction with the analysis process.
Analysis begins when a person decides that there is an information need and starts considering how to try to satisfy that need. Early activities include identifying relevant information sources and collecting useful-looking documents through some combination of searching and browsing. To support this phase of analysis, the workspace must allow the aggregation of information retrieved from various sources and encoded in a variety of representations. In our work, this is instantiated by visual symbols representing information being placed in a hierarchy of two-dimensional planes.
Once a set of documents is retrieved, the person browses and prioritizes the documents for further attention due to the frequently overwhelming amount of information and the scarcity of time for analysis. This activity, which has been described as information triage [9], is a rough categorization process where documents are skimmed and clustered into virtual piles or containers indicating initial perceived value.
As skimming occurs, task-based categories for the documents will start to emerge. Experience shows people will use whatever categorization mechanisms are available in the workspace – dividing documents into lists or piles, assigning visual attributes like color or shape, or creating containers for documents depending on the features of the workspace [9].
During formative interpretation, it is common for some documents to fall in-between categories or for a person to consider a document to be a member of a category but not like the other members of that category. Expression of these partial memberships occurs by documents being placed near piles or given similar (but not identical) visual attributes. This constructive use of visual ambiguity reduces the overhead of expressing hard-to-verbalize relationships, making it more likely people will represent formative interpretations in the system and thus record and potentially communicate these interpretations to others.
With a visual workspace, analysis proceeds by manipulating the visual representations of documents while constructing an interpretation of the task, domain, and source materials. It is natural for initial interpretations to be modified as the analysis proceeds. This requires workspaces to provide low-effort mechanisms for initial expression and later modification.
Not only do individual documents move from one category to another, but the categories themselves change – coloring a symbol red may mean it contains important information initially, while later on red indicates membership in a task-specific category. By enabling the flexible application of visual attributes, the workspace allows the codings to evolve with the user’s understanding of their task and domain. Over the course of an analysis, this often leads to the emergence of a visual language.
While providing freedom of expression for the analyst, workspaces are limited by the expressiveness of the modifiable visual attributes, the ease of manipulation of symbols and groups of symbols, and the perception of context for current and past interactions. These limitations have led to the visual analytic workspace described in the rest of this paper.
The Visual Knowledge Builder is a visual workspace for collecting, organizing, and sharing information following on our prior work on VIKI [8]. Besides lessons from experiences with VIKI, the design of the Visual Knowledge Builder has incorporated experiences with information authoring and sharing from the Virtual Notebook System [12] and experiences with information representation and formalization from the Hyper-Object Substrate [15].
While more a practical issue rather than a research issue, the Visual Knowledge Builder is written in Java and runs on Windows 98 and Windows NT. While we encountered much interest in using VIKI, initial excitement led to disappointment when hardware issues were discussed with potential users.
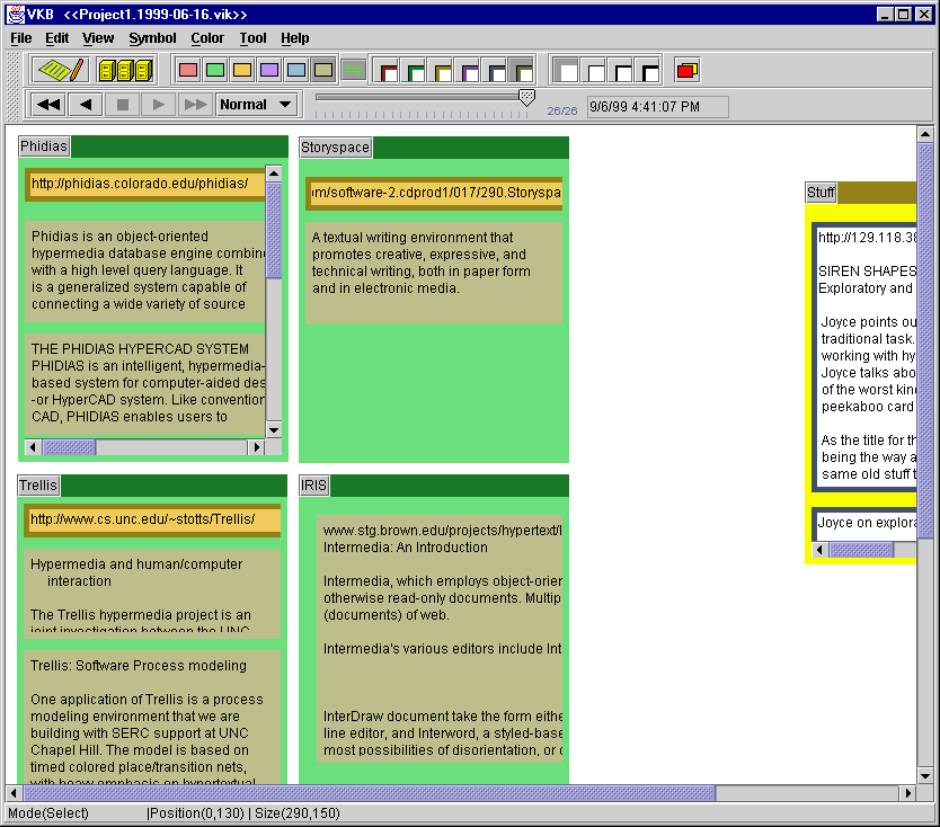
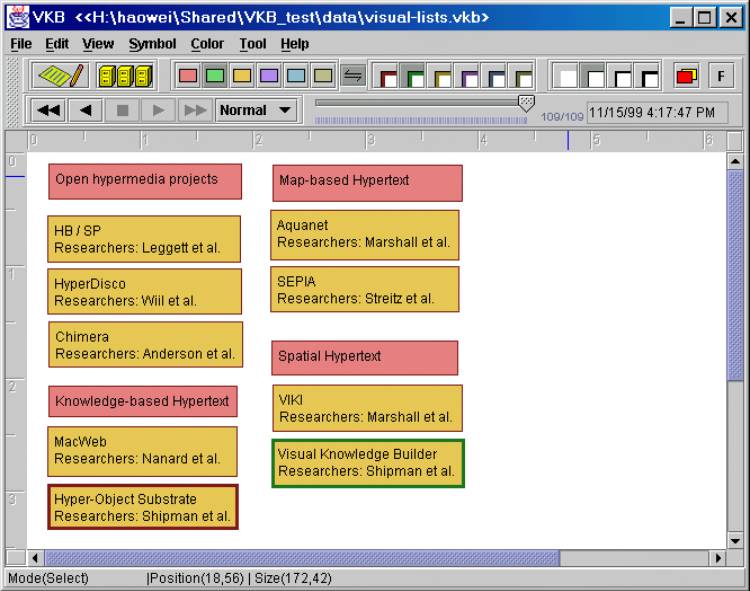
At first glance, the Visual Knowledge Builder is similar to VIKI. The two systems share the use of a hierarchy of two-dimensional collections that can contain other collections or visual symbols representing information objects. Users modify visual attributes for collections and symbols to indicate their interpretation of the information. Figure 1 shows a workspace with five visible collections containing a number of symbols from an undergraduate’s use of the system while writing a paper. The four green collections on the left – labeled Phidias, Storyspace, Trellis, and IRIS – contain information about four projects relevant to the student’s task while the fifth collection, colored yellow and labeled “Stuff”, contained other potentially useful information.
Expression of relationships and categories occurs by placing symbols near one another or placing symbols in a collection. Three of the four green project collections have a thick-bordered orange symbol at the top with a URL pointing to further information on the project. All four of these collections contain brown symbols with text chunks summarizing or directly taken from Web pages about the projects. This example illustrates the use of visual cues, such as color and size, to indicate the role of information.
Users may navigate in and out of collections by double clicking on the border of a collection. As with Boxer [5] and VIKI, navigating into a collection causes that collection to fill the workspace window. This exposes more of the lower-level workspace. Figure 2 shows the effect of navigating into the “Stuff” collection found on the right in Figure 1.
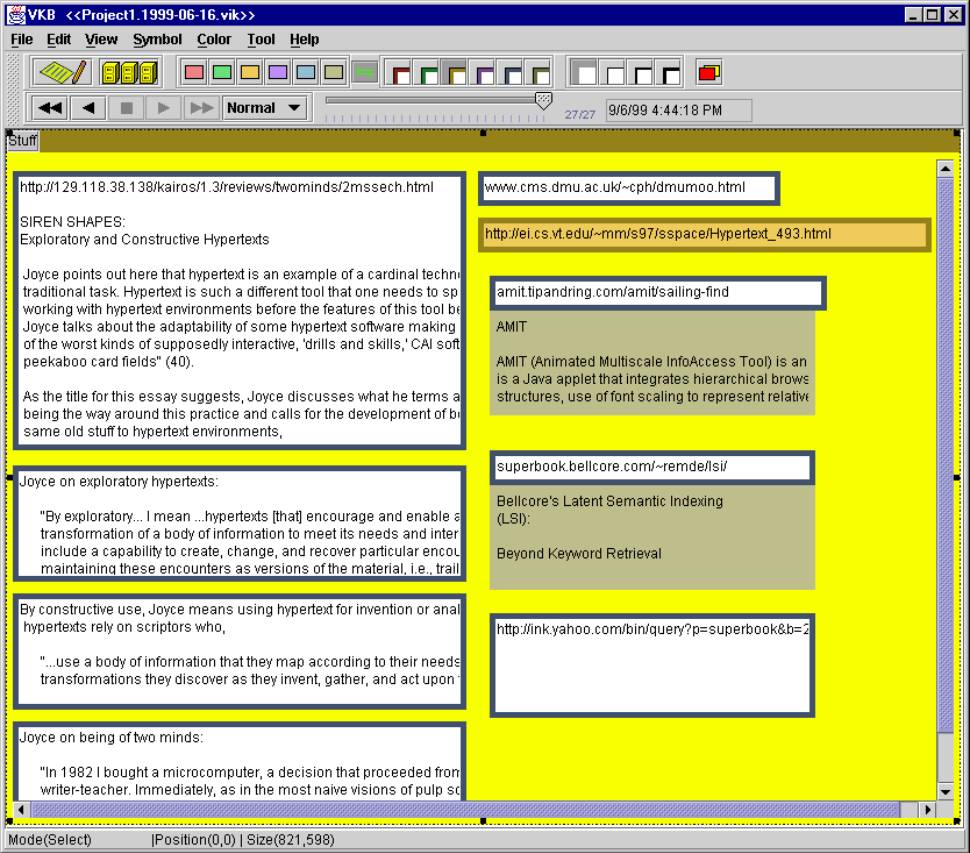
Most of the symbols in the “Stuff” collection have thick blue borders with white backgrounds. The content of these symbols includes both text and URLs pointing to further sources. There are also examples of both the thick-bordered orange symbol containing a URL and the brown text symbols seen in the other collections in Figure 1.
The symbols in Figures 1 and 2 are the visual representation of underlying information objects in the Visual Knowledge Builder. More than one visual symbol can represent the same information object – an information object may be presented as an small orange symbol in one location and as a large blue symbol in another. In this way the user can express multiple interpretations of a single piece of content.
Information objects consist of a set of attributes and values. The attributes and values for an object may change at any time during the analysis to allow the incremental formalization of content [15]. There are a few special attributes used by the system: a generic textual content formalization of content attribute stores the content for free-form objects and another special attribute identifies information from other applications. Objects can combine a set of attributes and values represented in the Visual Knowledge Builder with a pointer to external information, like MS Word or Excel files, documents on the Web, or any other data type with a registered Windows viewer application.
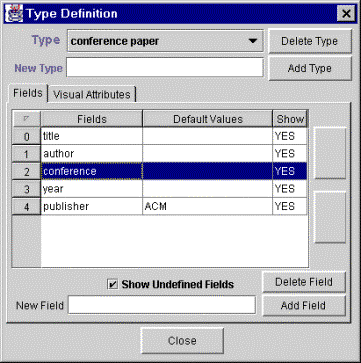
When a common set of attributes is shared by a number of objects, the user can create an object type. Types combine semantic information about the object (in the form of a set of expected attributes and their default values) and visual information about the symbols (as default visual characteristics). Information in the type definition may be overridden at the object or symbol level, thus not all objects of a particular type have the same set of attributes and not all symbols for objects of a particular type have the same visual characteristics.
The type definition dialog, shown in Figure 3, is used to specify the visual and semantic attributes for a type. It also allows the user to choose which attributes and values are shown in the visual symbol and the order in which they are shown. For example, in the context of looking at documents while writing a paper the user may initially present the date and publisher of the documents to identify the most recent articles from reputable sources. Later the user may display the more unique title and author information. [**** too detailed? ****]
The Visual Knowledge Builder’s semantic representation is similar to that of the Hyper-Object Substrate [15]. This representation includes relationships between objects, inheritance of attributes among objects, and default values for attributes. This enables attribute-based searching and the ability to actively support the formalization of relationships implied in the layout of the symbols or in the textual content of the objects. Later we describe how the knowledge represented in the Visual Knowledge Builder can be exported as XML for use in other applications.
As described above, the main mode of interacting with information in the Visual Knowledge Builder is the visual manipulation of symbols and collections in the workspace. For symbols and collections, the position, size, border width, font style, transparency, and background, font, and border colors are modified by direct manipulation or by buttons on the toolbar.
The color system in the Visual Knowledge Builder includes a modifiable set of background and border color pairs. Our experience indicates that color pairs are often desired, but that users occasionally want to bring attention to a particular piece of information of a common type by giving it a similar, but not identical, color scheme. For this reason, the pairing of background and border colors can be broken. [**** too detailed? ****]
Transparent symbols and collections result from potential users requests for symbols that are part of the space (blend into the background of the collection) rather than obviously separate symbols stuck on the space. This is analogous to writing on the butcher paper that is being used for pinning up 3”x5” cards. The text of transparent symbols and collections is displayed on the parent collection’s background but their manipulation is otherwise normal. [**** should this be in here? ****]
Part of expression using the Visual Knowledge Builder is the construction of spatial structures indicating relationships between the symbols. A survey of workspace use in Aquanet [6] and other computational and non-computational settings found people creating piles, lists, and repeating patterns of visual symbols to indicate relationships between documents or chunks of information [7]. The Visual Knowledge Builder includes and improves upon the resulting spatial parser built to recognize these structures and hierarchic click-selection for iterating through levels of the inferred structure [13].
The spatial parser, as originally developed for Aquanet and integrated into VIKI, recognizes three main types of structures: stacks, lists, and composites. Composites are repeating visual patterns of symbols or specific types. All objects in Aquanet had a user-defined type and VIKI’s use of the spatial parser used an explicit object type when recognizing structures. Because many objects are left untyped during an analysis (this is especially true early in the analysis process), we have added a preprocessor that attaches implicit types to untyped objects based on the visual appearance of the symbol.
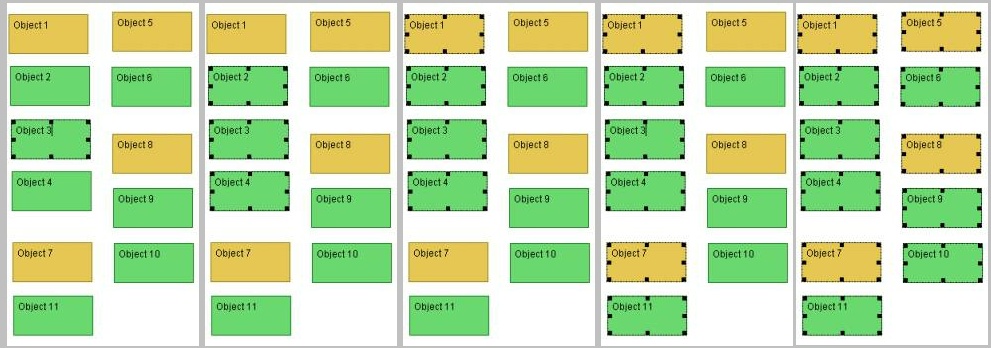
To determine when untyped symbols are considered to be of the same type, the parser uses a visual difference function that compares the border and background color, border width, height, and width of two symbols. When the value of this difference function is greater than a preset value, two symbols are considered visually dissimilar. To make type an associative property, a symbol only has to be visually similar to one member of an implicit type to be considered a member of that type. While this has the potential to consider very visually dissimilar symbols to be of the same type if there are intermediate states among the other symbols, this has not been an issue in practice.
The visual features available for modification and the recognition of visual structures are intertwined. An example of this is how the decision to separate the background and border color influences the implicit typing mechanism. Color tends to dominate people’s visual categorization of symbols and thus played the largest role in determining new types in the initial implicit typing algorithm. By allowing border colors to be independent of background colors, there are now two variables to consider instead of one. Our current experience indicates that background color is still the dominant factor for an object’s type. When not kept in its normal connection to the background color, the background color tends to be used as a modifier. See Figure 6 for an example of one such border variation. Thus our new implicit typing algorithm weighs differences in background color higher than differences in border color.
As mentioned earlier, the visual languages used to express emergent interpretations evolve over time. Because of this symbols may be given particular visual features early in a task, while later the meaning of those features has changed.
Since people rarely go back to make the information space completely consistent, this can lead to the inability to interpret or misinterpretations later in the task. Also, while individuals normally remember their encoding scheme for recent tasks, when more than one person is working on a workspace or when long periods of time pass between uses of a workspace, the knowledge of what a particular visual feature means is not always available.
For both of these reasons, the Visual Knowledge Builder includes an embedded history mechanism similar to Reeves’ work on INDY [10]. This mechanism allows users to rewind, replay, or step through the interpretive process leading to the current workspace.
Figures 1 and 2 show the history components on the toolbar. The buttons on the left act like a VCR for playing through the history. The slider in the middle shows where the displayed state is in the event list and allows the user to quickly move to specific states in the history. On the right is the timestamp for the modification event that left the workspace as it is being displayed.
Besides being able to scroll through the history, users can ask a symbol to return to a particular event. Reeves found returning to the state of the original event aided in disambiguating deictic references (“this” and “that” referring to nearby objects) in annotations on a computer network design. Similar to the evolution of the visual coding scheme in the workspace, Reeve’s network designers found later design efforts made understanding results and comments of earlier tasks more difficult [10].
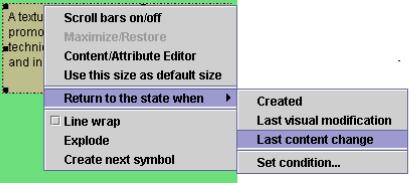
In the Visual Knowledge Builder, the primary interpretive events are those creating a symbol and object, moving a symbol, changing a symbols visual appearance, and editing the content of an object. By selecting the “Return to state when” button on the popup menu attached to a symbol or collection, the user can quickly return to the context of a particular interpretive event. Figure 5 shows the popup menu for returning to prior events. To get further back in the history of the symbol, the user can select this option multiple times.
Initial uses of the Visual Knowledge Builder have included taking notes at workshops and collecting information for another research project. Issues that arise in such applications are the difficulty of sharing the contents of a workspace with others not using VKB and the difficulty of making use of VKB content in another application. How can the contents of the workspace, including the spatial interpretation, textual information, and more formalized knowledge, be exported for people using other information tools?
To address these difficulties, VKB can export information into textual, HTML, and XML formats. VKB exports the hierarchic organization indicating what information object is in what collection. The implicit nature of patterns contained in the workspace limits the visual and spatial content that can be usefully exported. VKB uses the implicit structures recognized by the spatial parser to order the objects within each collection. For example, the recognized structure from Figure 6 would be exported as the XML seen in Figure 7.
This example points out the potential for inferring semantic relationships based on visual layout. The author of the visual structure in Figure 6 is categorizing projects and we would like to represent that categorization in the resulting XML. There are a couple choices for representing this information: it could be represented as an explicit relationship between the two XML objects or as a text attribute added to the elements of the list whose value is the text from the label. There are many potential rules for using the spatial structure when exporting XML and such semantic inferences based on visual layout is a focus area of our on-going research.
Preliminary versions of the Visual Knowledge Builder have been in use for four months. Uses include shorter-term tasks by a visiting high-school teacher collecting Internet materials for her class and longer-term tasks by an undergraduate student using the system to collect information from the Internet while writing reports.
A chemistry teacher from a local high school used the Visual Knowledge Builder during her two-week visit to our campus. Her use of the system was to collect chemistry related information for her students that will be given to high school students as resources for chemistry projects.
This effort made heavy use of the ability of symbols to point to information available on the Internet. One of the difficulties the teacher had was getting chunks of information (e.g. pieces of a Web page) into the system. Initially she had to locate the information, then create a symbol, then select and copy the information and paste it into the symbol. To facilitate the easier collection of information, we added the ability to create symbols with the current contents of the cut buffer. Users can indicate whether they always, never, or only once want to paste the contents of the cut buffer into the next object created.
At the time this paper is being written, the high schools are just starting the new academic year and the students in the chemistry class have not yet used the system or the resources collected by the teacher.
The most extensive use of the Visual Knowledge Builder has been by an undergraduate student from the mathematics department who is investigating different technologies and their potential use. The goal of his projects were to write reports about “web workspaces” and “information extraction”.
He was given a demonstration of the Visual Knowledge Builder and told to collect information in the system while writing his reports. Each of the two tasks took about a month, including the time for learning the basics on the topic, collecting and reading information (primarily from the Internet), and writing the report. After looking at the information workspaces, we interviewed the student to better understand what was in the workspace, how it was organized, and why.
As the version of the system used by the student did not contain the embedded history mechanism, we collected 17 and 10 states of the information workspace for the “web workspaces” and “information extraction” tasks respectively. Figures 1 and 2 are the information workspace from early in the information collection process for the first task (the third of the 17 states.) At this point, the student has created collections for information about four projects deemed relevant (PHIDIAS, Storyspace, IRIS, and Trellis) and another collection for “Stuff”, which he described in the interview as information he “hadn’t gotten to” or that “didn’t fit on the left.”
At the end of the writing task, the system- and project-oriented collections had all been moved into another collection (called “Hypermedia Applications”) and the top-level of the information space contained objects with ideas generated by the student or very general information like definitions. This change in analytic task from collection to writing was echoed in the interview when he said that by then he “understood more” about the domain and the top-level collection now contained information for his main task which was to “write the report.”
This partial separation of source content from generated content maps to some writing systems, like Smith’s Writing Environment [16] or the GMD’s Sepia [17]. These systems had separate spaces for different phases of the writing task. While this separation did occur in the first task, it did not occur in the second.
The second task, writing a report on “information extraction”, resulted in an information space very different from the first task. Figure 8 shows the top half of the top-level collection in the middle of the second task. The bottom half contained more symbols and collections, uniformly colored and frequently overlapping. In this task, source documents and the student’s writings share the top-level space.
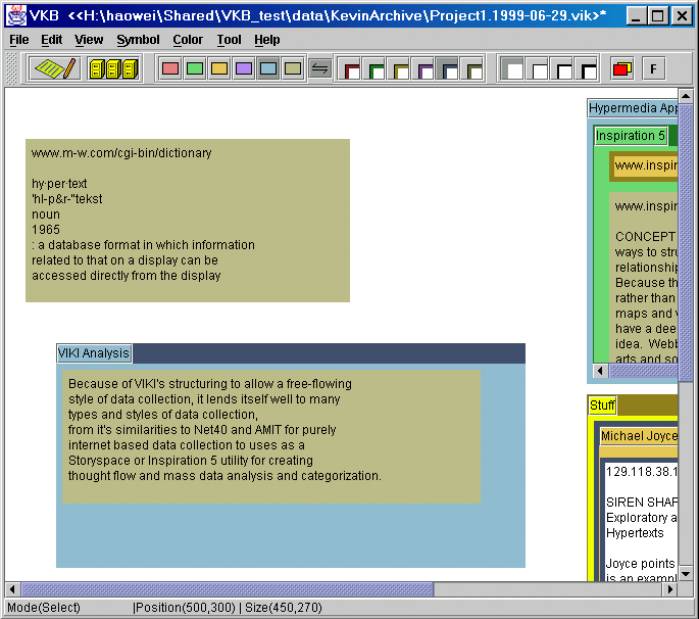
When asked about the size and use of the top-level space in the second task, the student said the top information had been sorted while the bottom area would either go into “Stuff” or was not yet sorted. Despite the visual clutter, the student could explain the use of color for grouping information into general concept collections (in gold), project and system collections (in green), with white symbols most often containing text the student had written and blue symbols being links to Web information.
Another obvious difference in the two information spaces is the amount of regular structure. Even early in the first task, there was a set visual representation for information about projects and student notes (shown in Figures 1 and 2.) The regularity of structure disappeared in the second task. There are a number of potential reasons for this difference.
After the two tasks were complete but before the interview, the student claimed to be more interested in the second task, asking more about the area and if he could help design such a system. Could this enthusiasm for the task/domain take away the emphasis on creating visual patterns?
Looking back at prior experience indicates another possibility. In a study comparing the use of VIKI to the use of paper technologies for a short-term analysis task [9], it was noted that users of the system were less concerned with reading documents and were more concerned with the comprehensibility of their results (improving the visual structure.) Could the novelty of the visual workspace cause new users to emphasize visual regularity while later on this effect subsides?
When asked directly about the regularity of the first space and the lack of regularity in the second, the student said there “are many different approaches” to organizing the information in the second task and the categories were still in flux. The student’s recognition of alternative structures led him to postpone structuring the space until he understood more. He viewed the first task as “more straightforward” and that, in the second task, he had gone “more in-depth” and “moved on to theory.” These comments indicate the enthusiasm may have played a role in differences in the two spaces, if only leading him to think about alternative structures.
The long-term use by the student generated a number of suggestions for features. Many of these were suggestions for features found in systems the student was used to – e.g. adding control keys for text editing. One interesting request was for the ability to scroll collections by “grabbing” the background of the collection and moving the mouse. Due to limitations on screen space and the large number of collections, the student kept the scrollbars on most collections hidden except when needed. Grab-based scrolling made moving objects between collections considerably more efficient. Another interesting request was for “object exploding”, causing an object to be broken up into smaller objects, as found in Storyspace [1]. Since the Web pages and articles the student found frequently contained a number of different ideas and concepts, breaking an object up into smaller chunks that could be manipulated separately became common practice. The most recent update to the Visual Knowledge Builder contains both of these features.
The growing use of unedited information sources increases the need for people to become information analysts, looking for corroborating evidence, deciding what sources are believable and developing interpretations based on information from numerous sources. Analytic information workspaces provide a place for this activity to occur.
The Visual Knowledge Builder is designed based on experiences with prior analytic workspaces. Users create a hierarchy of two-dimensional spaces for collecting and arranging visual symbols containing information. The Visual Knowledge Builder:
Use of the Visual Knowledge Builder led to facilities for sharing workspaces with people not using the system, and improvements in acquiring and manipulating information. Initial experiences with long-term use create questions about the effects of the technology on analytic practice. While earlier studies of short-term analysis tasks showed a change in emphasis from reading and interpreting to the presentation of results, the results of long-term use indicate this may be a novelty effect and wear away with time or be a function of interest in the task.
This research emphasizes the human-interpretation of information through emergent visual languages. Other information workspaces focus on information collection (e.g. Web Squirrel [2], Web Forager [3], and DLITE [4]) or visualization (e.g. Data Mountain [11]). Together, these results point to the potential for analytic workspaces supporting all phases of the analytic process.
This work was supported in part by grant IIS 9734167 from the National Science Foundation. We thank Cathy Marshall for her helpful comments on this work.
Bernstein, M., Bolter, J.D., Joyce, M., and Mylonas, E. 1991. Architectures for Volatile Hypertext. In Proc. of ACM Hypertext ’91, ACM, New York, 243-260.
Bernstein, M. 1996. Web Squirrel. Eastgate Systems, Watertown, MA.
Card, S., Robertson, G., and York, W. 1996. The WebBook and the Web Forager: an information workspace for the World-Wide Web. In Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI ’96). ACM, New York, 111-118.
Cousins, S. B., Paepcke, A., Winograd, T., Bier, E., and Pier, K. 1997. The digital library integrated task environment (DLITE). In Proceedings of ACM Digital Libraries ’97 Conference. ACM, New York, 142-151.
diSessa, A., and Abelson, H. 1986. Boxer: A Reconstructible Computational Medium. Communications of the ACM, 29, 9, 859-868.
Marshall, C.C., Halasz, F., Rogers, R., and Janssen, W. 1991. Aquanet: a hypertext tool to hold your knowledge in place. In Proceedings of ACM Hypertext `91 Conference. ACM, New York, 261-275.
Marshall, C.C., and Shipman, FM. 1993. Searching for the Missing Link: Discovering Implicit Structure in Spatial Hypertext. In Proceedings of ACM Hypertext ’93. ACM, New York, 217-230.
Marshall C.C., and Shipman, F.M. 1995. Spatial Hypertext: Designing for Change. Communications of the ACM, 38, 8 (August 1995), 88-97.
Marshall C.C., and Shipman, F.M. 1997. Effects of Hypertext Technology on the Practice of Information Triage. In Proceedings of ACM Hypertext `97 Conference, ACM, New York, 167-176.
Reeves, B. 1993. Supporting Collaborative Design by Embedded Communication and History in Design Artifacts. Ph.D. Dissertation, Department of Computer Science, University of Colorado.
Robertson, G., Czerwinski, M., Larson, K., Robbins, D., Thiel, D., and van Dantzich, M. 1998. Data Mountain: Using Spatial Memory for Document Management, In Proc. of ACM UIST `98, ACM, New York, 153-162.
Shipman, F.M., Chaney, R.J., and Gorry, G.A. 1989. Distributed Hypertext for Collaborative Research: The Virtual Notebook System. In Proceedings of ACM Hypertext ’89 Conference, ACM, New York, 129-135.
Shipman, F.M., Marshall, C.C., and Moran, T.P. 1995. Finding and Using Implicit Structure in Human-Organized Spatial Layouts of Information. In Proc. of the ACM Conference on Human Factors in Computing Systems (CHI ’95), ACM, New York, 346-353.
Shipman, F.M., Marshall, C.C. and LeMere, M. 1999. Beyond Location: Hypertext Workspaces and Non-Linear Views, In Proceedings of ACM Hypertext `99 Conference, ACM, New York, 121-130
Shipman, F.M., and McCall, R. 1999. Supporting Incremental Formalization in the Hyper-Object Substrate, ACM Transactions on Information Systems, 17, 2, 199-227.
Smith, J.B., Weiss, S.F., and Ferguson, G.J. 1987. A Hypertext Writing Environment and its Cognitive Basis. In Proceedings of ACM Hypertext ’87 Conference, ACM, New York, 41-50.
Streitz, N. Hannemann, J., and Thuring, M. 1989. From Ideas and Arguments to Hyperdocuments: Travelling through Activity Spaces, In Proceedings of ACM Hypertext ’89 Conference, ACM, New York, 343-364.