Frank Shipman
Selected Research Projects
|
Social Media Ownership @ Texas A&M University and Microsoft Research, with Cathy Marshall As more and more content is created and shared within social media applications and services, ownership is becoming increasingly difficult to determine. Twitter conversations, Amazon reviews and Facebook commentary are examples of how the creative activities of many join together in ways that challenge traditional concepts of content authorship and ownership.
Studying people's beliefs and practices regarding |
|
|
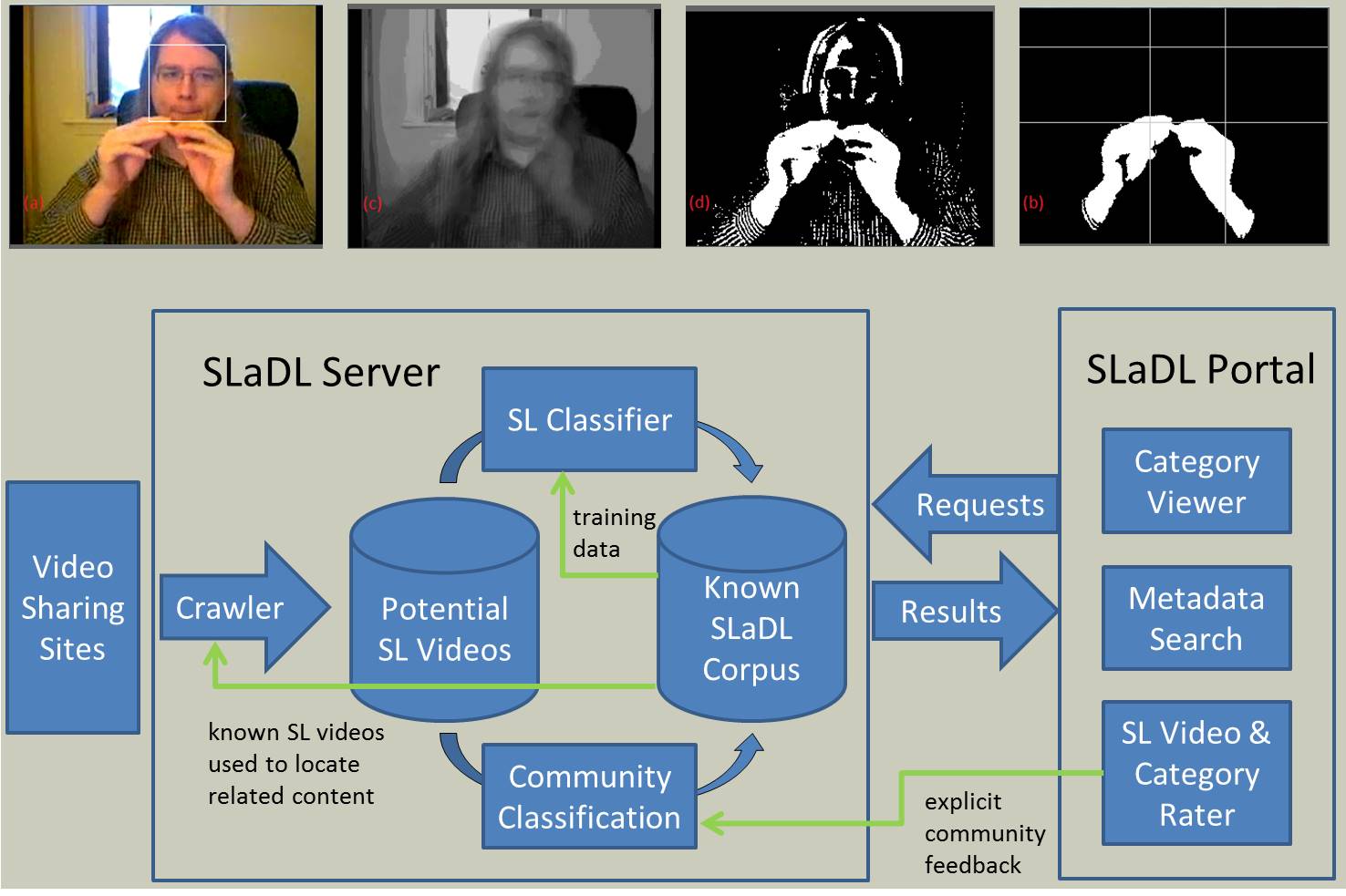
Sign Language Digital Library (SLaDL) @ Texas A&M University, with Caio Duarte Monteiro, Ricardo Guterrez-Osuna, and others Access to sign language (SL) content poses a number of challenges for existing ingestion, location, and management capabilities. This project explores the potential for automatic processing of content combined with community involvement and novel user interfaces to improve the sign language community's access to content. Activities of the project include an assessment of the difficulty of SL access, techniques for detecting SL activity using video features, and techniques for distinguishing between different sign languages using video features. The project also explores the more general problem of infrastructure for identifying community-oriented video libraries within large video sharing sites like YouTube. |
|
Data Triage and Analysis @ Texas A&M University, with Suinn Park Collecting, triaging, and analyzing heterogeneous data is a challenge due to the separation of data by media or type and the separation of activity across tools for different phases of the overall analysis process. This project applies the lessons learned from prior work supporting text and image analysis in human-authored visual workspaces to the problem of heterogenous data analysis. An initial focus has been the development of techniques for interacting with and visualizing time-stream data in visual workspaces and techniques for recommending data objects based on prior user activity as seen in the design of PerCon. |
|
|
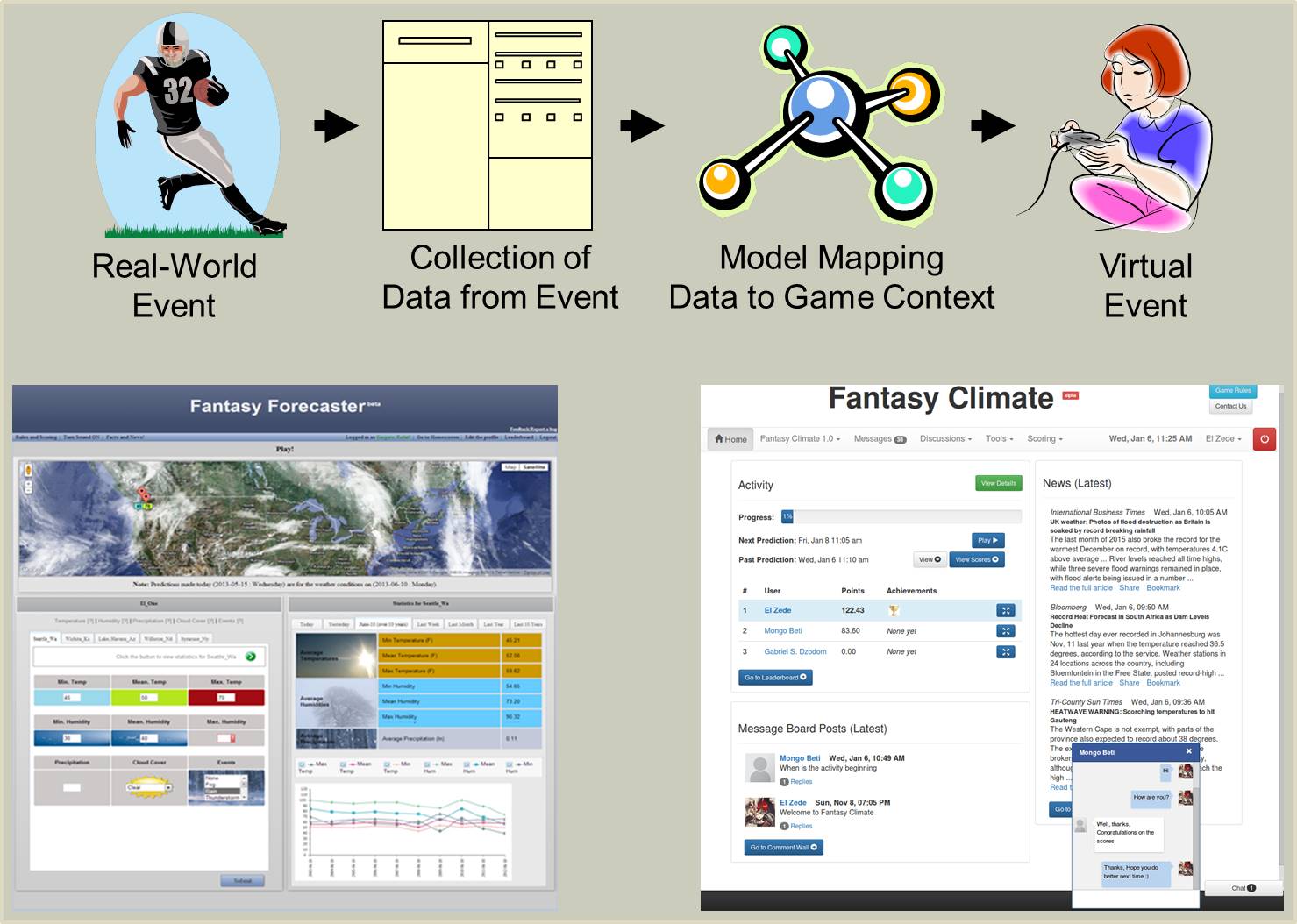
Prediction Games @ Texas A&M University, with Gabriel Dzodom and many others Games involving the prediction of future performance or activity (e.g. Fantasy Sports) encourage engagement with data. This project investigates the practices of players of existing prediction games, the development of a domain-independent prediction game engine, and the design of prediction games in new domains. We are particularly interested in the application of such games to data science education. This project began by understanding the history of and developing a model of fantasy sports. This involves understanding the practices of fantasy sports players. Based on this analysis we have developed initial data-driven prediction games to motivate data analysis skills and rich domain knowledge. |
|
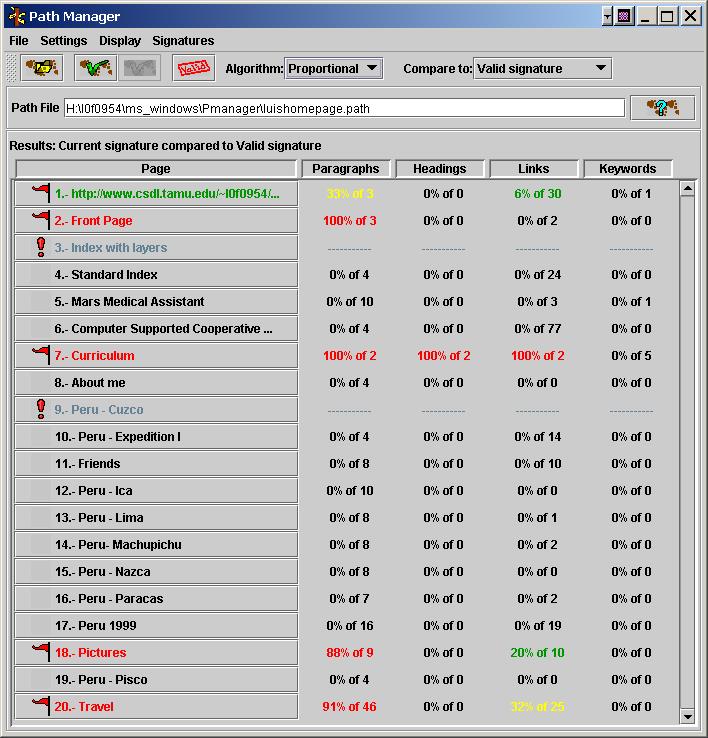
Distributed Collection Manager @ Texas A&M University, with Luis Francisco-Revilla, Paul Bogen, and others The Distributed Collection Manager provides support for maintaining distributed collections, such as lists of web-based resources. Current research is on algorithms for identifying and determining the importance of change to resources and interfaces for presenting results. |
|
|
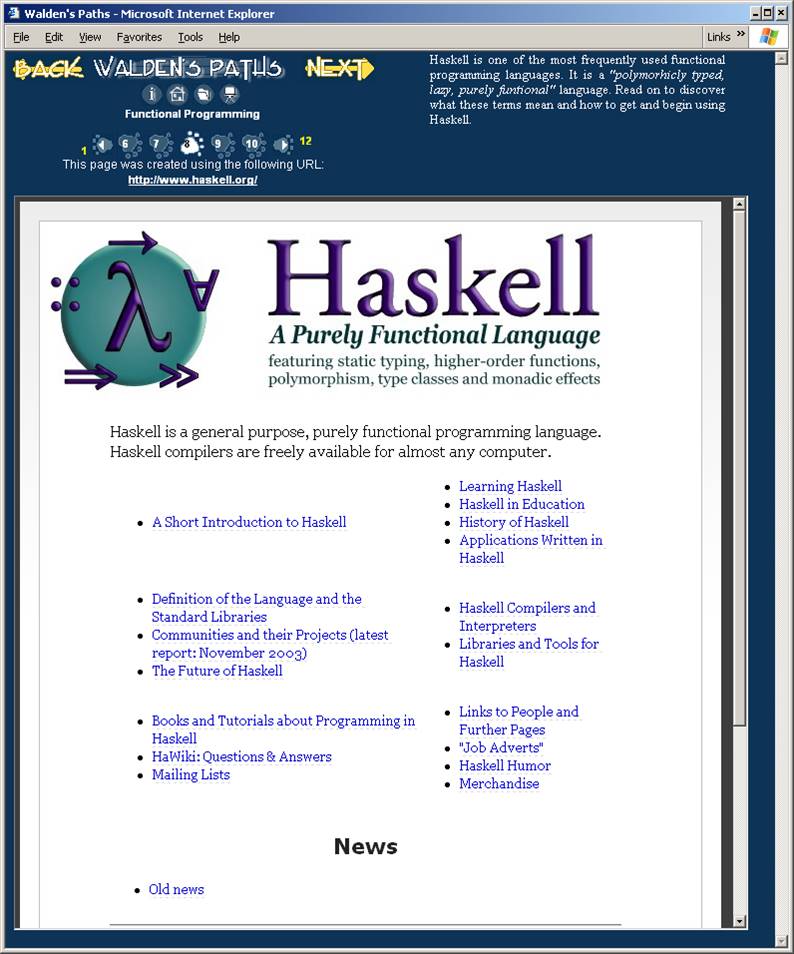
Walden's Paths @ Texas A&M University, with Richard Furuta and many others Walden's Paths is a set of tools for authoring, distributing and viewing paths composed of annotated web pages. Paths can be static or dynamically generated. Current research emphasizes the design of template-based authoring tools that help authors create pedagogically sound paths for education. |
|
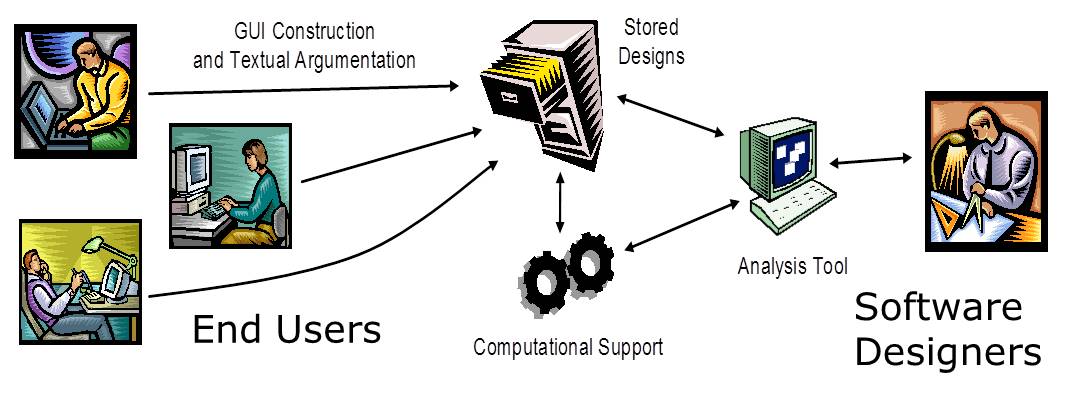
Design Exploration @ Texas A&M University, with J. Michael Moore Design Exploration is a process aimed at increasing the quality of early-stage software requirements by collecting large quantities of input from stakeholders. The research includes the design, implementation, and evaluation of tools for collecting annotated partial designs from stakeholders and effectively browsing, searching, and analyzing large collectionsof these designs. |
|
|
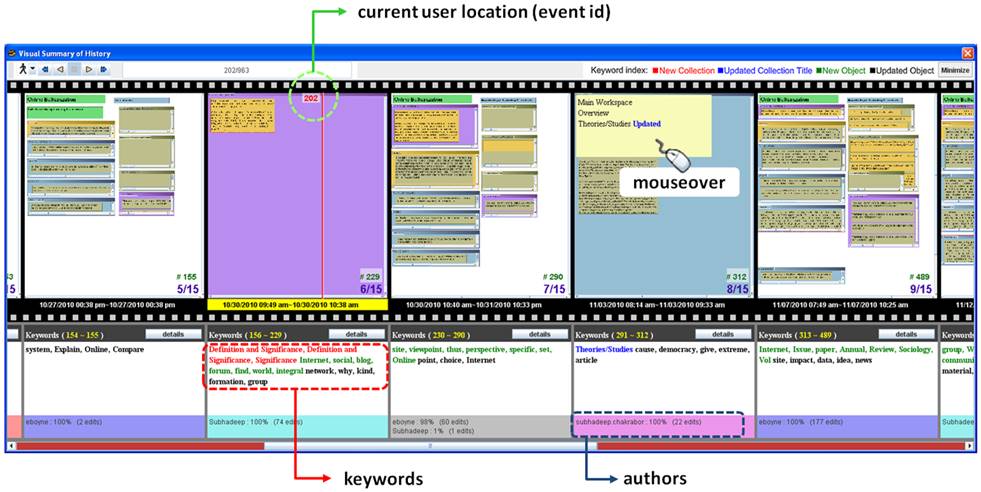
Authoring History Visualization @ Texas A&M University, with DoHoung Kim Many applications place users into collaborations with unknown and distant partners. Collaboration between participants in such environments is more efficient if individuals can identify and understand the contributions of others. A traditional approach to supporting such understanding within the CSCW community is to record user activity for later access. Issues with this approach include difficulties in locating activity of interest in large tasks and that history is often recorded at a system-activity level instead of at a human-activity level. To address these issues, we developed CoActIVE, a history mechanism that clusters records of user activity and extracts keywords from manipulated content in an attempt to provide a human-level representation of history. |
|
Multi-Application Interest Modeling @ Texas A&M University, with Soonil Bae, Sampath Jayarathna and others To support document triage, we have developed an extensible multi-application architecture that initially includes an information workspace and a document reader. An Interest Profile Manager infers users' interests from their interactions with the triage applications, coupled with the characteristics of the documents they are interacting with. The resulting interest profile is used to generate visualizations that direct users' attention to documents or parts of documents that match their inferred interests. The novelty of our approach lies in the aggregation of activity records across applications to generate fine-grained models of user interest. |
|
|
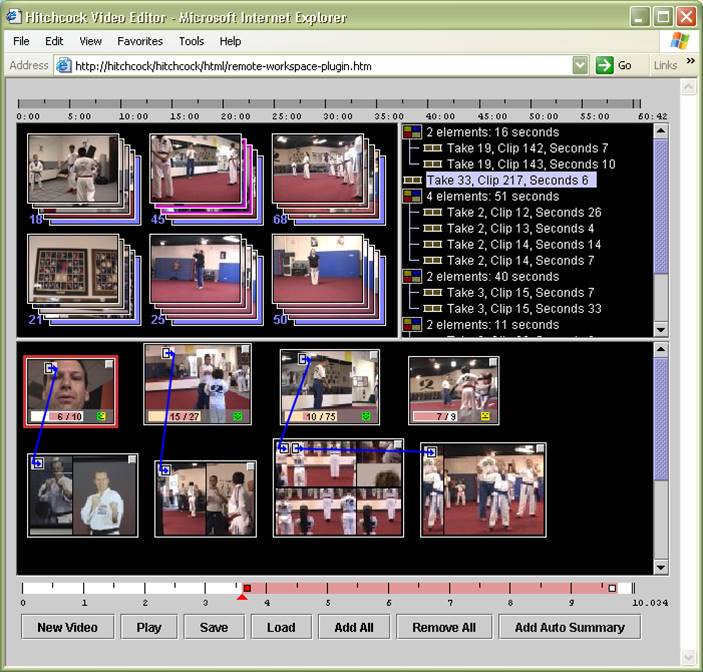
Hyper-Hitchcock @ FX Palo Alto Laboratory, with Andreas Girgensohn and Lynn Wilcox Hyper-Hitchcock consists of three components for creating and viewing a form of interactive video called detail-on-demand video: a hypervideo editor, a hypervideo player, and algorithms for automatically generating hypervideo summaries. Detail-on-demand video is a form of hypervideo that supports one hyperlink at a time for navigating between video sequences. The Hyper-Hitchcock editor enables authoring of detail-on-demand video without programming and uses video processing to aid in the authoring process. The Hyper-Hitchcock player uses labels and keyframes to support navigation through and back hyperlinks. Hyper-Hitchcock includes techniques for automatically generating hypervideo summaries of one or more videos that take the form of multiple linear summaries of different lengths with links from the shorter to the longer summaries. |
|
WARP @ Texas A&M University, with Luis Francisco-Revilla WARP is a Web-based dynamic spatial hypertext that runs in a Web browser. WARP includes the ability to transclude other spatial hypertexts as collections. WARP also enables annotation and other content manipulation to be preserved in personal reading sessions. WARP uses a variety of presentation adaptations to contextualize the spatial hypertext's display. In particular WARP uses a variable number of models to guide adaptation in response to multiple relevant factors. Behaviors in WARP help preserve perceptual structures that may be lost due to adaptation and user interaction. |
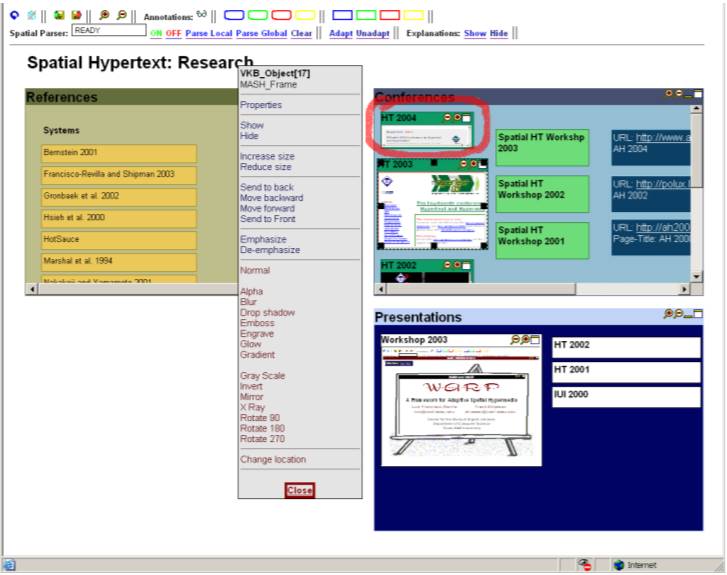
|
|
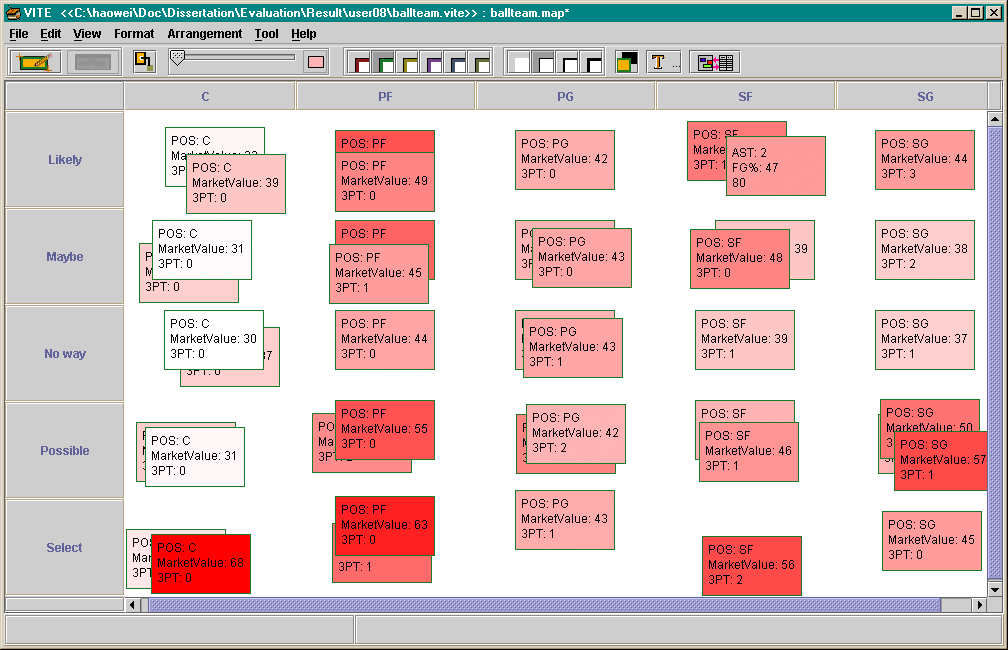
VITE @ Texas A&M University, with Haowei Hsieh VITE is a visual workspace that supports two-way mapping for projecting structured information to a two-dimensional workspace and updating the structured information based on user interactions in the workspace. This is related to information visualization, but reflecting visual edits in the structured data requires a two-way mapping from data to visualization and from visualization to data. VITE provides users with an interface for designing two-way mappings. |
|
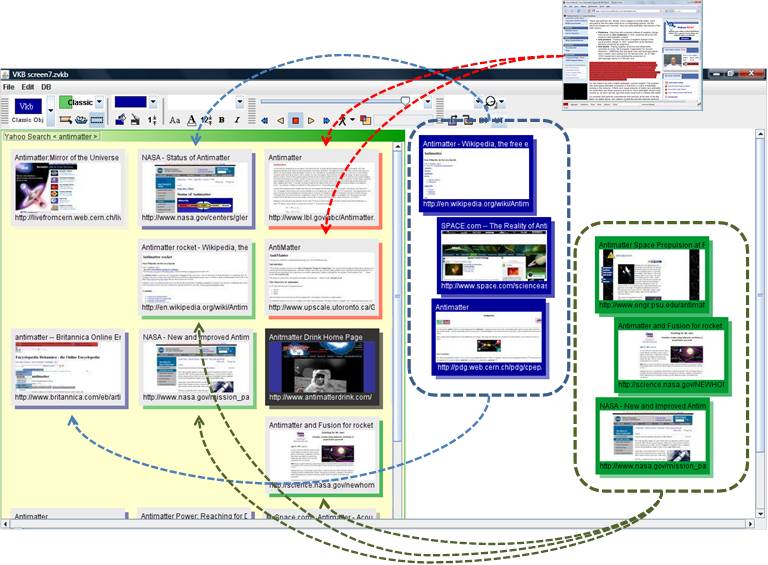
Visual Knowledge Builder @ Texas A&M University, with Haowei Hsieh and many others The Visual Knowledge Builder is a spatial hypertext environment for working with a variety of information. Current research directions include adaptive visualizations based on inferred user interest and improved support for collaboration via improved interaction history. |
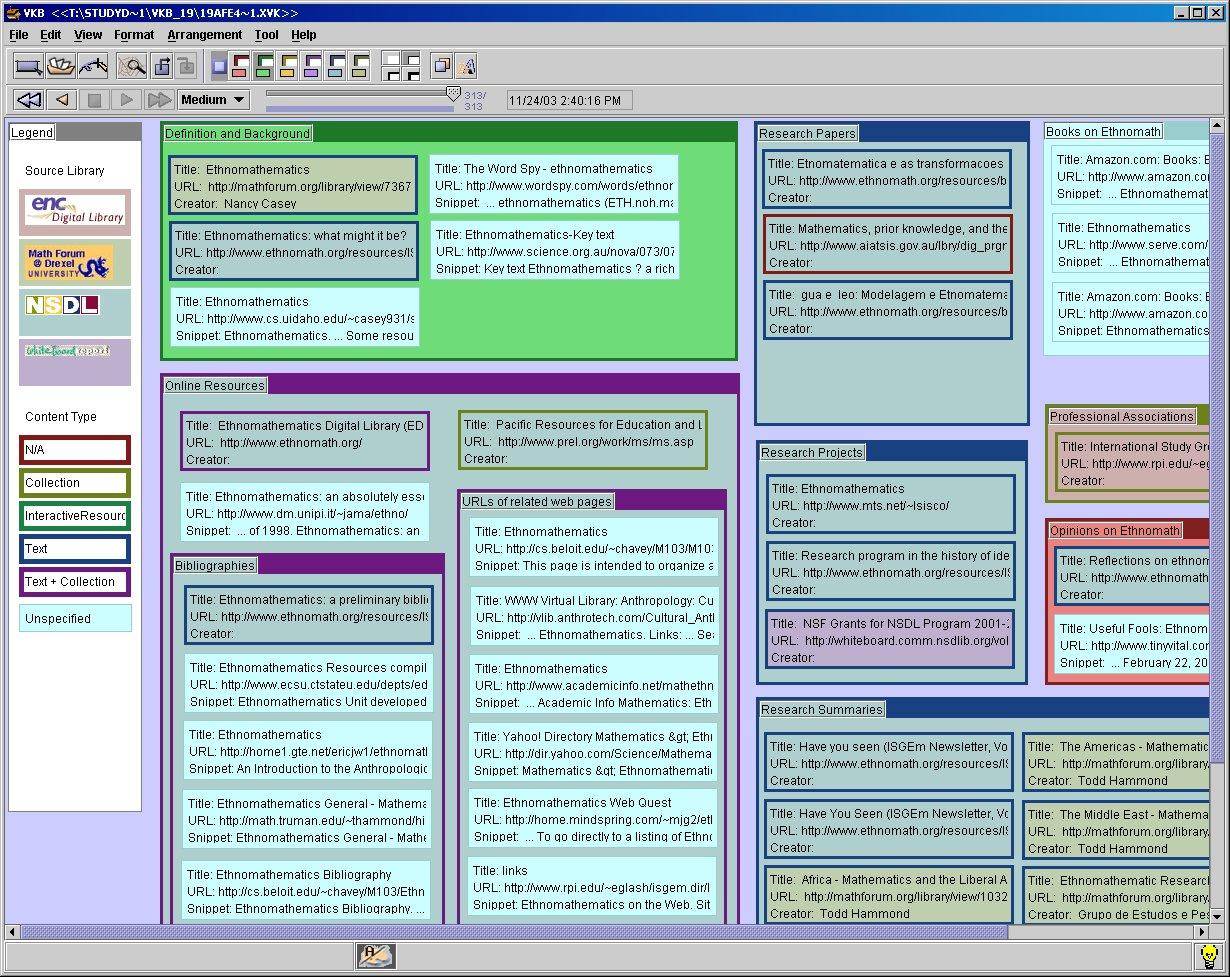
|
|
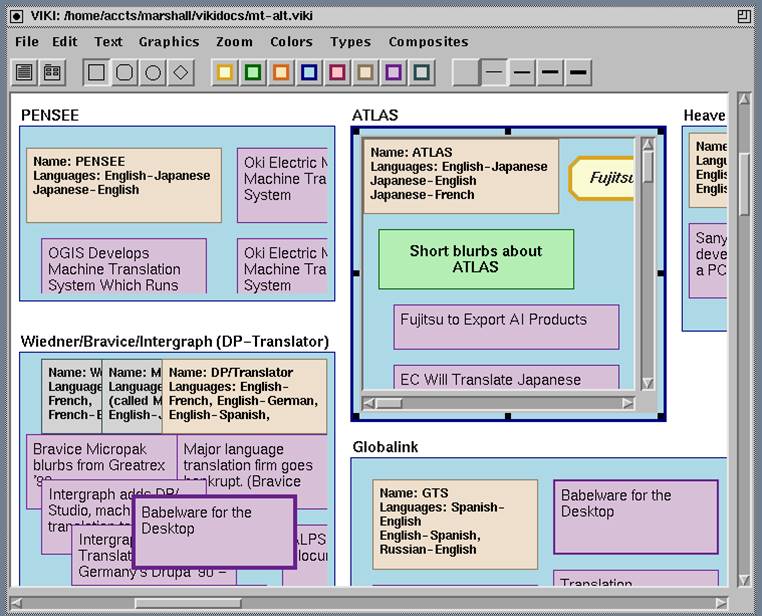
VIKI @ Xerox PARC & Texas A&M University, with Cathy Marshall and Jim Coombs Experience with systems aimed at encouraging formal representation of domain knowledge found that users were much more likely to imply relationships between objects through visual layout and other means than they were to use system represenations of such relations. VIKI was designed to ease the development and use of such emergent visual languages. It included a spatial parser that would recognize common patterns in human-generated layouts of information in order to reason over the information/knowledge in the environment. |
|
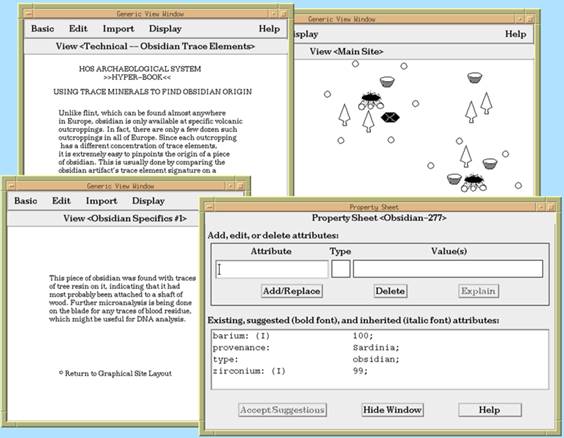
Hyper-Object Substrate (HOS) @ University of Colorado, Boulder Combining both hypermedia and knowledge-based system representations, HOS was designed to support incremental formalization, a process where users enter content in lower-effort human-readable form (e.g. text and layout) and the system supported the development of a knowledge-based representation of some of the content. It did this by recommending attributes for and relationships between information objects. Recommendations were generated based on simple text processing. |
|
|
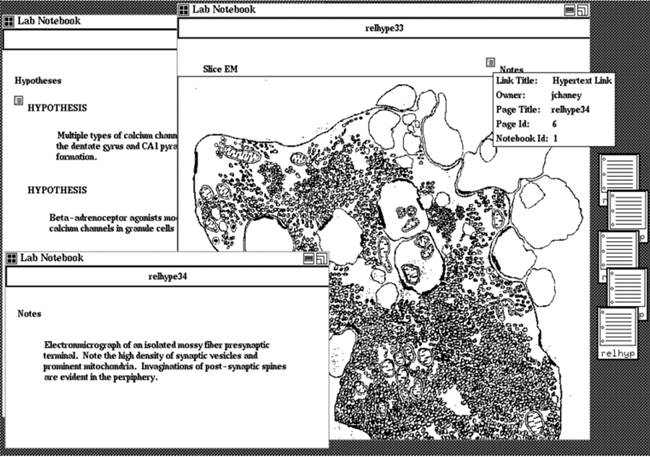
Virtual Notebook System (VNS) @ Baylor College of Medicine, with Tony Gorry, Andy Burger, Jesse Chaney, and others The VNS was developed to support the collaborative authoring and sharing of multimedia content in a distributed hypertext. Developed prior to the WWW, the system had a unified editing and viewing interface, enabled importing content from a variety of on-line sources, and provided UNIX-like access control at the notebook, page, and individual object level. |