
Best Viewpoints for External Robots or Sensors Assisting Other Robots
Best Viewpoints for External Robots or Sensors Assisting Other Robots

Best Viewpoints for External Robots or Sensors Assisting Other Robots
Best Viewpoints for External Robots or Sensors Assisting Other Robots
INTRODUCTION
An assistant robot providing a view of a task being performed by a primary robot has emerged as the state of the practice for ground and underwater robots in homeland security applications, disaster response, domestic robots, and inspection tasks. Advances in small unmanned aerial systems (UAS), especially tethered UAS, and personal satellite assistants such as SPHERES suggest that flying assistant robots will soon supply the needed external visual perspective or even shine a spotlight on dark work areas.
During the 2011 Fukushima Daiichi nuclear power plant accident, teleoperated robots were used in pairs from the beginning of the response to reduce the time it took to accomplish a task. iRobot PackBots were used to conduct radiation surveys and read dials inside the plant facility, where the assistant PackBot provided camera views of the first robot in order to manipulate door handles, valves, and sensors faster. QinetiQ Talon unmanned ground vehicles (UGVs) let operators see if their teleoperated Bobcat end loader bucket had scraped up a full load of dirt to deposit over radioactive materials.
Two iRobot PackBots working together to open a door during the Fukushima Daiichi nuclear accident.

Since then, the use of two robots to perform a single task has been formally acknowledged as a best practice for decommissioning tasks, e.g., cutting and removing a section of irradiated pipe. However, the Japanese Atomic Energy Agency (JAEA) has reported that operators constantly try to avoid using an assistant robot. The two sets of robot operators find it difficult to coordinate with the other robot in order to get and maintain the desired view but a single operator becomes frustrated trying to operate both robots. However, two robots are better than one. In 2014, an iRobot Warrior costing over $500 000 was damaged due to the inability to see that it was about to perform an action it could not successfully complete. The experienced operator had declined to use an assistant robot. Not only was this a direct economic loss, the 150 kg robot was too heavy to be removed without being dismantled and thus cost other robots time and increased their risk as they have to navigate around the carcass until another robot could be modified to dismantle it.
The public safety sector is also using pairs of robots in order to help the primary robot work efficiently, timely, and reliably in highly unstructured environments ranging from a subway station to the inside of a mobile home. Indeed, robotics companies are beginning to offer small marsupial UGVs that ride on the larger UGV and are deployed as needed. At the Deepwater Horizon spill, an assistant underwater remotely operated vehicle (ROV) was used to help position the primary ROV so that it could insert the cap to the stop the leaking oil. However, after the insertion of the cap, the primary ROV bumped into the observing ROV and careened into the cap. The cap had to be removed, repaired, and reinstalled, adding several days to the overall mitigation.
There are at least three issues with the current state of the practice. First, it increases the cognitive workload on a primary operator by either having to coordinate with a secondary operator or requiring the primary operator to control two robots, creating safety, logistical, and teamwork problems. Second, it is not guaranteed a human operator will provide an ideal viewpoint as viewpoint quality for various tasks is not well understood and humans were shown to pick suboptimal viewpoints. Third, while there are studies that make the assistant robot autonomously select a viewpoint, the current research lack principles to select ideal viewpoints.
The goal of this project is to create the formal theory of value of different external viewpoints of a robot performing tasks. This theory will provide an understanding of what are the best viewpoints for actions of the primary robot and can be used as a basis for principled viewpoint selection for an assistant robot. This can ultimately guide autonomous implementations of robotic visual assistants eliminating the need for a secondary operator while providing provably the best viewpoint.
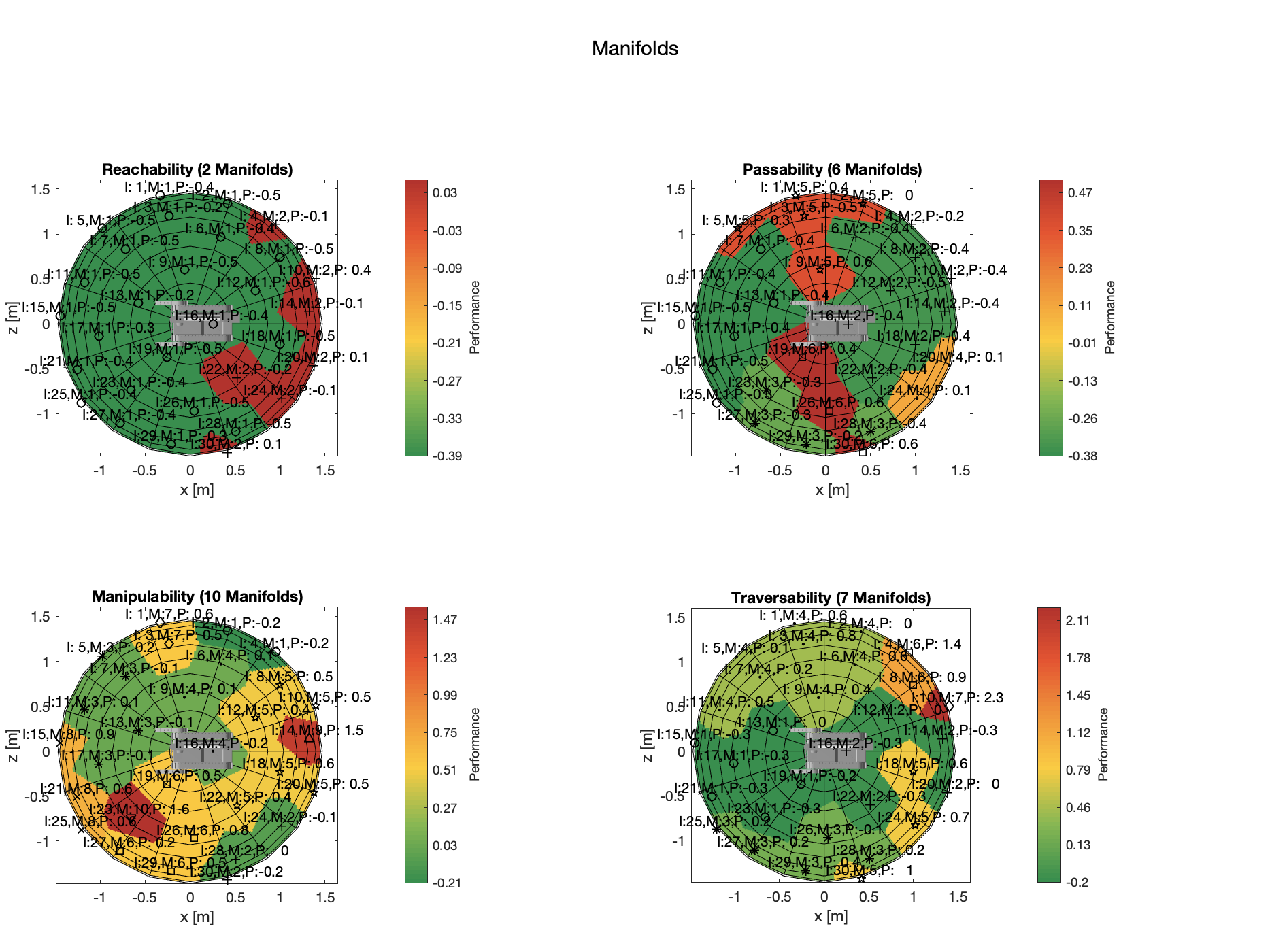
The research question posed in this project is: What is a formal theory for selecting the best external viewpoints for viewing actions performed by a robot? This research question has two subquestions. First, can the value of viewpoint from an assistant at a specific location be ranked independently of a task, environment, and robot models by using affordances, that is, can we derive a theory of viewpoints based on psychophysical behavior? Second, can viewpoints of similar value be clustered into a small number of regions called manifolds providing equivalent performance?
APPROACH
The approach of this project is to use the cognitive science concept of Gibsonian affordances, where the potential for an action can be directly perceived without knowing intent or models, and thus is universal to all robots and tasks. In this approach, tasks are decomposed into affordances, space around the task is decomposed into viewpoints, and the viewpoints for the affordances are rated based on teleoperator’s psychophysical behavior and clustered into manifolds of equivalent value.
An overview of the main building blocks of the approach.
The main postulation of the approach is that a formal theory of viewpoint selection can be created using Gibsonian affordances. This formal theory of viewpoints has two central tenets. First, the value of a viewpoint depends on the Gibsonian affordance for each action in a task. Second, viewpoints in the space surrounding the action can be rated and adjacent viewpoints with similar ratings can be clustered into manifolds of viewpoints with the equivalent value.
The formal theory of viewpoints is extracted in two steps. First, the value of viewpoints |v| is quantified in a human subject study using a computer-based simulation. The value is quantified for four Gibsonian affordances (TRAVERSABILITY, MANIPULABILITY, REACHABILITY, PASSABILITY). Second, adjacent viewpoints of similar value is clustered into manifolds of viewpoints with the equivalent value. The clustering is done using agglomerative hierarchical cluster analysis.
REACHABILITY affordance: Is the robot and its manipulator in the right pose to reach an object?
PASSABILITY affordance: Is the robot or its manipulator in the right pose to safely pass through a narrow opening?
MANIPULABILITY affordance: Is the robot’s manipulator in the right pose to manipulate an object?
TRAVERSABILITY affordance: Is the robot in the right pose to safely traverse the environment?

IMPLEMENTATION
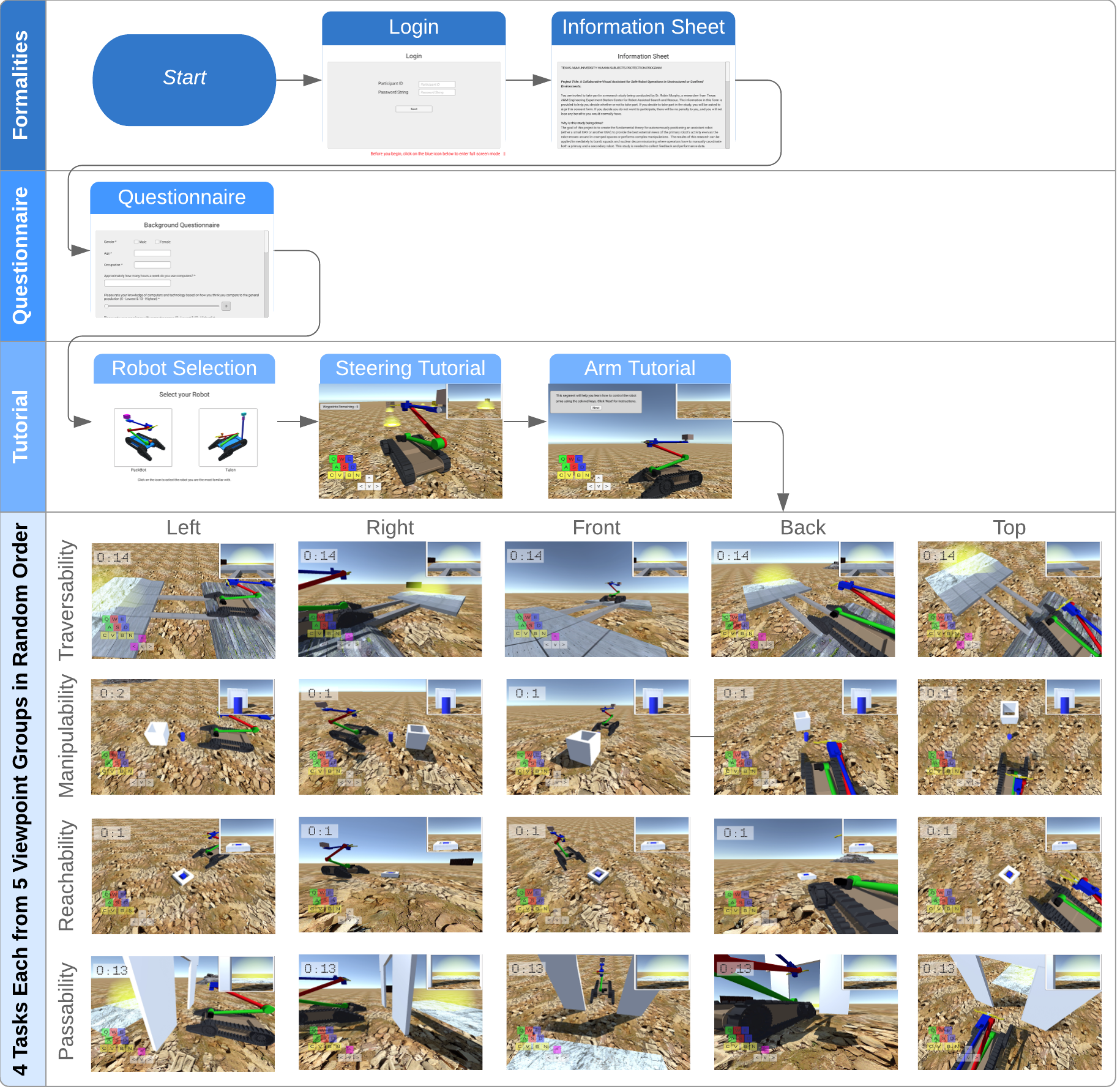
A computer-based simulator was created to enable quantification of the value of viewpoints by remotely (over the web) measuring the performance of expert robot operators controlling one of two common explosive ordnance disposal (EOD) robots in four tasks corresponding to the four affordances from different external viewpoints. The simulator was implemented in C# using Unity engine and runs on Amazon Web Services (AWS) infrastructure.
The simulator screen as seen by the participants shows the external view of the task from a specific viewpoint.

EXPERIMENTATION
Experimentation is divided into two parts. The first is quantifying the value of 30 viewpoints in a 30 person human subject study for 4 Gibsonian affordances (MANIPULABILITY, PASSABILITY, REACHABILITY, and TRAVERSABILITY) using a computer-based simulator. The second is using the data from the human subject study to rank the viewpoints and cluster adjacent viewpoints with similar value into manifolds of equivalent value using agglomerative hierarchical clustering.
A 30 person human subjects study was designed with a goal to sufficiently sample human performance for 30 viewpoints v to formalize the value of viewpoints |v| for each of the 4 affordances so that spatial clusters (manifolds) can be learned. The subjects perform 4 tasks corresponding to the 4 affordances from varying external viewpoints while their performance is measured in terms of time and number of errors to quantify the corresponding viewpoint value.
Seven main steps of the experimental procedure.
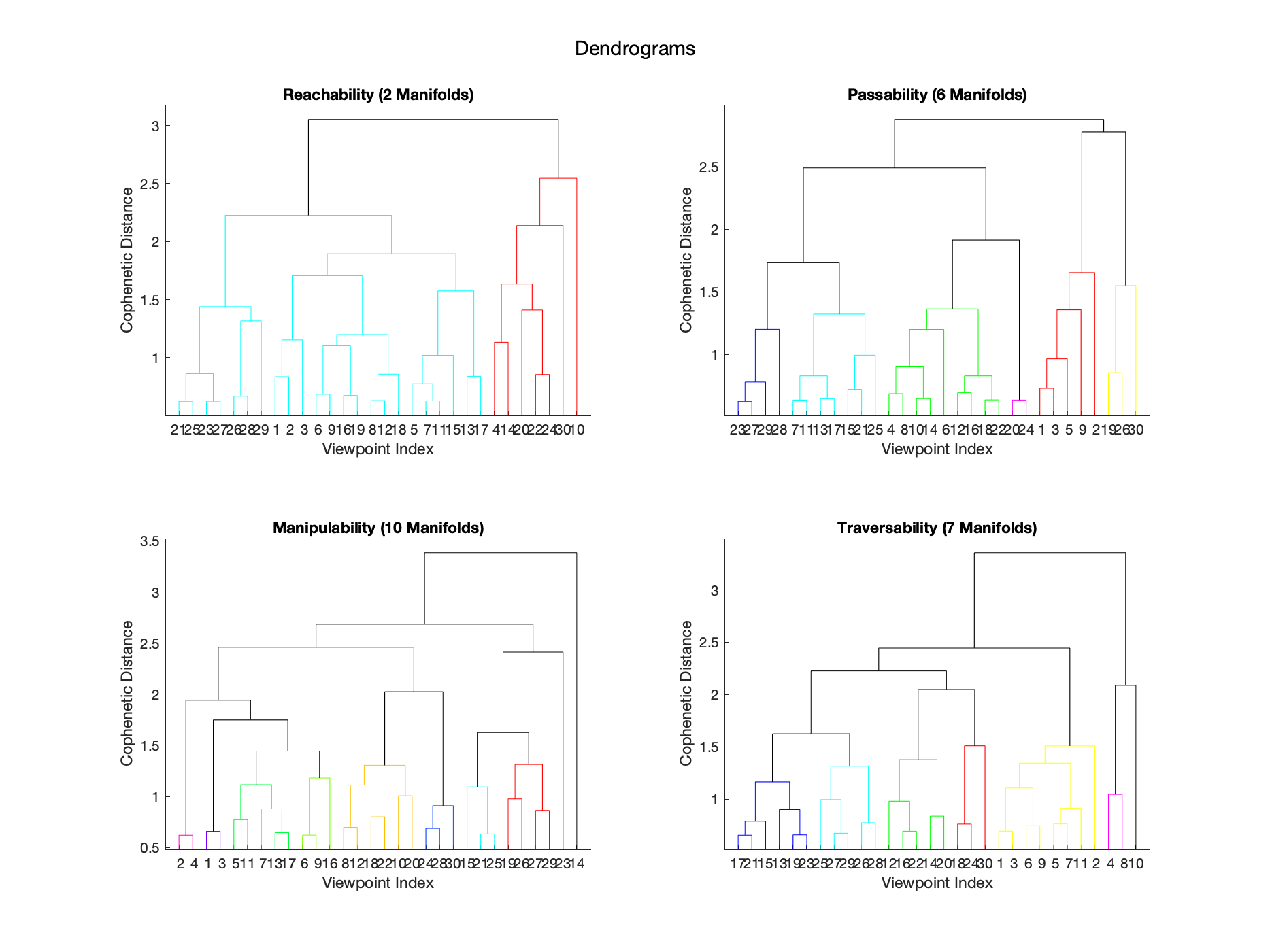
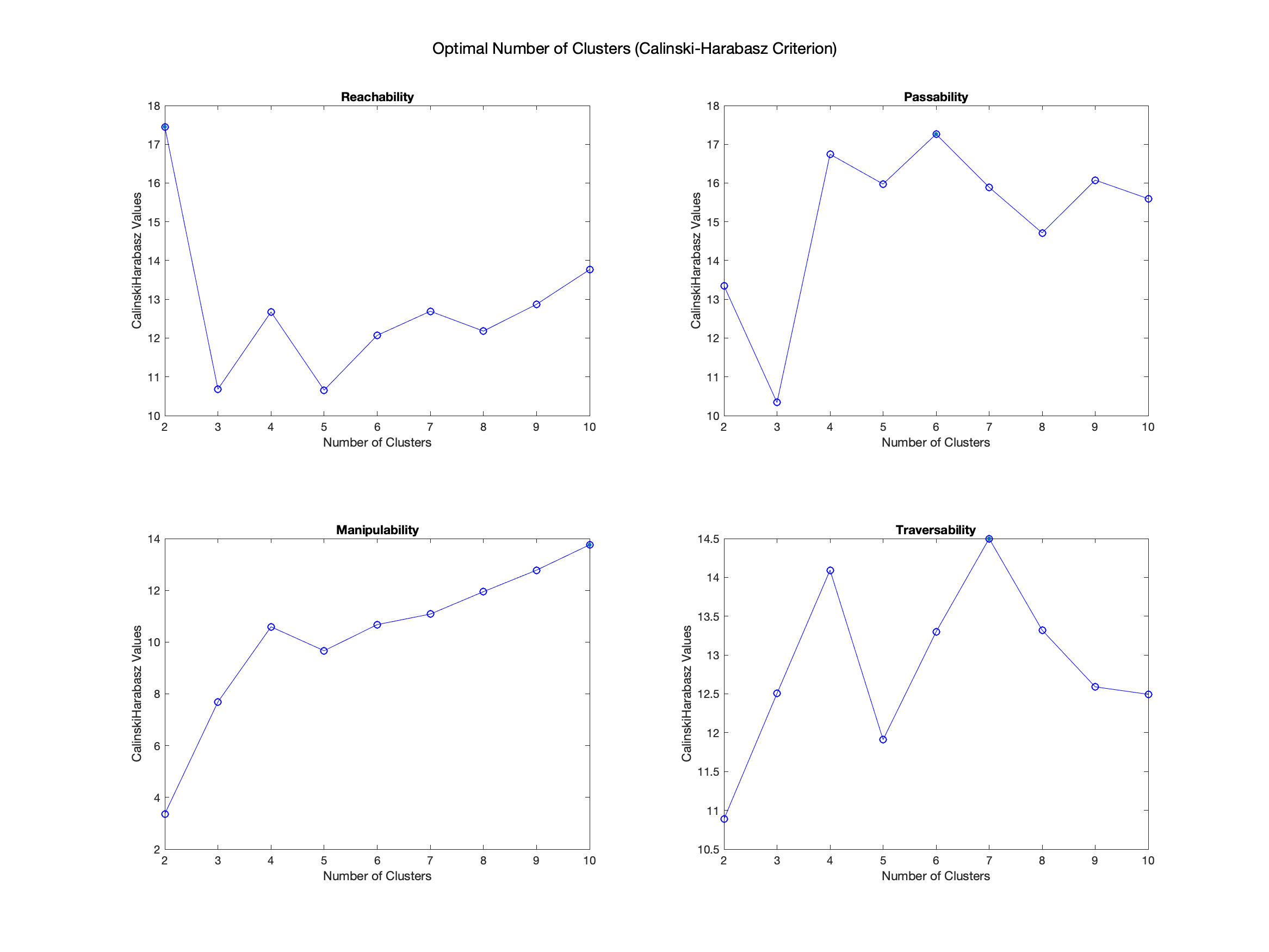
Agglomerative hierarchical cluster analysis with average linkages is used to generate manifolds. This method is appropriate because it considers the proximity of viewpoints, does not require the number of clusters in advance, and handles outliers in a favorable way. Pairwise dissimilarity is computed using standardized Euclidean distance and used to construct a hierarchical cluster tree using the unweighted pair group method with arithmetic mean linkage. Calinski-Harabasz criterion is used to cut the tree to produce the optimal number of manifolds.
RESULTS
Hierarchical clustering resulted in 2 manifolds with cophenetic correlation coefficient of 0.6 for REACHABILITY, 6 manifolds with cophenetic correlation coefficient of 0.73 for PASSABILITY, 10 manifolds with cophenetic correlation coefficient of 0.66 for MANIPULABILITY, and 7 manifolds with cophenetic correlation coefficient of 0.67 for TRAVERSABILITY.
Resulting manifolds for each affordance.
Dendrograms corresponding to the manifolds for each affordance.
Calinski-Harabasz criterion was used to find the optimal number of clusters.
There is a statistically significant difference in viewpoint value for different manifolds for all affordances. This implies that not all views are equal and some manifolds are statistically significantly better than others. This was tested using unbalanced one-way ANOVA test for each affordance.
The found best manifold is statistically significantly better than the found worst manifold for each affordance in terms of viewpoint value it provides. This was tested using one-tailed two-sample t-test (left-tailed).
Viewpoint values are statistically significantly different for different affordances because there is an interaction between affordance factor and viewpoint factor. This was tested using unbalanced two-way ANOVA test for interaction effects.
Selected robot has no influence on viewpoint values because it was not confirmed that there is an interaction between robot factor and viewpoint factor. This was tested using unbalanced two-way ANOVA test for interaction effects.
FUNDING
CONTACT
Department of Computer Science & Engineering
Texas A&M University
301 Harvey R. Bright Building
College Station, TX 77843-3112
Email: robin.r.murphy@tamu.edu