Synthesizing Light Field From a Single Image
with Variable MPI and Two Network Fusion
SIGGRAPH Asia 2020
-
Qinbo Li
Texas A&M University -
Nima Khademi Kalantari
Texas A&M University



Abstract
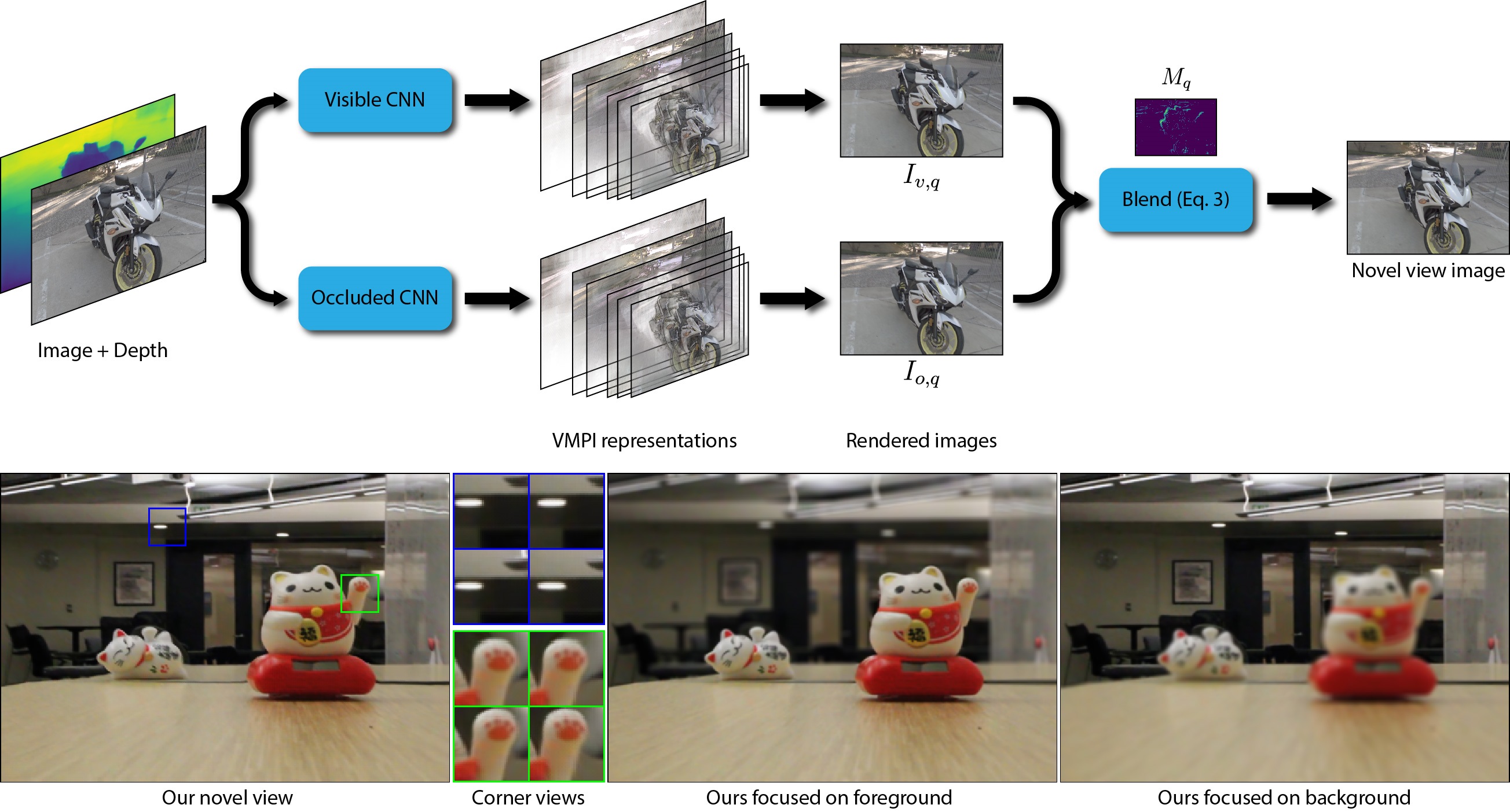
We propose a learning-based approach to synthesize a light field with a small baseline from a single image. We synthesize the novel view images by first using a convolutional neural network (CNN) to promote the input image into a layered representation of the scene. We extend the multiplane image (MPI) representation by allowing the disparity of the layers to be inferred from the input image. We show that, compared to the original MPI representation, our representation models the scenes more accurately. Moreover, we propose to handle the visible and occluded regions separately through two parallel networks. The synthesized images using these two networks are then combined through a soft visibility mask to generate the final results. To effectively train the networks, we introduce a large-scale light field dataset of over 2,000 unique scenes containing a wide range of objects. We demonstrate that our approach synthesizes high-quality light fields on a variety of scenes, better than the state-of-the-art methods.
Technical Video
BibTeX
@article{Li2020LF,
author = {Li, Qinbo and Khademi Kalantari, Nima},
title = {Synthesizing Light Field From a Single Image
with Variable MPI and Two Network Fusion},
journal = {ACM Transactions on Graphics},
volume = {39},
number = {6},
year = {2020},
month = {12},
doi = {10.1145/3414685.3417785}
}
Acknowledgements
We thank the anonymous reviewers for their constructive comments.
This work was funded in part by a TAMU T3 grant 246451.
The website template was borrowed from Michaël Gharbi.