Lecture 5: Out-of-order Execution
Review of the Model
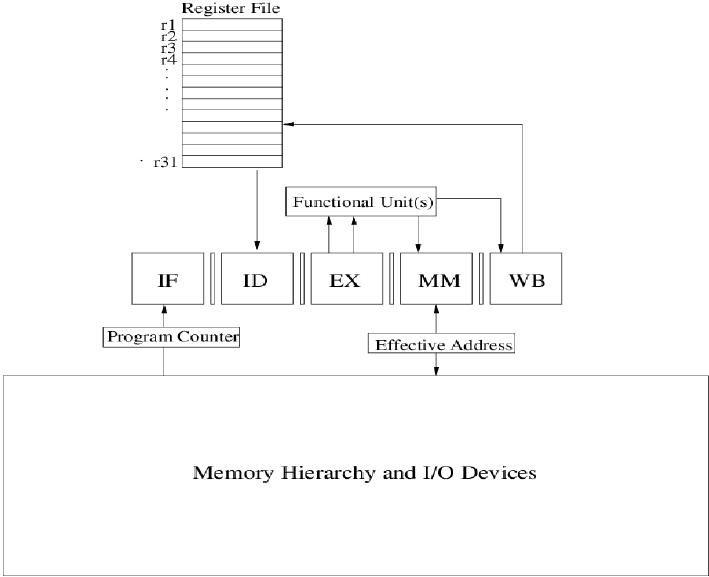
The following diagram roughly represents the general model you should have in
your mind of the main components of the computer:
Instruction Scheduling
Before we talk about out-of-order execution, let's remember how execution
proceeds in our standard pipeline. Instructions are fetched, decoded,
executed, etc. The decode stage is where we find out about structural,
data, and control hazards. The hardware does what it can to minimize
the impact of these hazards, but it is really up to the compiler to
schedule dependent instructions far away from each other to
avoid hazards. For instance, obviously, the compiler should "hoist"
loads as far back into the past as possible to avoid RAW hazards from
dependent instructions. Also, the compiler should avoid scheduling
instructions close together that will complete for some limited resource
such as a multiplier unit to avoid a structural hazard. Unfortunately,
the compiler is limited by several factors:
- It can't affect the microarchitecture; it must deal only with the
ISA. It can use what it knows about the microarchitecture to schedule
intelligently, but can only indirectly affect what happens at run-time.
- When the microarchitecture changes, the scheduler must be rewritten to
deal with the new details. Old programs should theoretically be recompiled,
but in practice an OS and other software is often distributed with binaries
optimized for the older version of the architecture to avoid incompatibilities.
- The compiler has to deal with non-uniform latencies and aliasing
ambiguities brought on by having a memory system. The compiler can only
guess at what will be happening at run-time, but can't actually observe
run-time behavior at a granularity that allows for better scheduling.
So, it might be better to have the job of instruction scheduling done in the
microarchitecture, or shared between the microarchitecture and the compiler.
Out-of-order Execution
The pipelines we have studied so far have been statically scheduled
and inorder pipelines. That is, instructions are executed in
program order. If a hazard causes stall cycles, then all instructions up
to the offending instruction are stalled until the hazard is gone. As we
have seen, forwarding, branch prediction, and other techniques can reduce
the number of stall cycles we need, but sometimes a stall is unavoidable.
For instance, consider the following code:
ld r1, 0(r2) // load r1 from memory at r2
add r2, r1, r3 // r2 := r1 + r3
add r4, r3, r5 // r4 := r3 + r5
Suppose that r3 and r5 are ready in the register file.
Suppose also that the load instruction misses in the L1 data cache, so
the load unit takes about 20 cycles to bring the data from the L2 cache.
During the time the load unit is working, the pipeline is stalled. Notice,
however, that the second add instruction doesn't depend on the value of
r1; it could issue and execute, but the details of our inorder
pipeline prevent that because of the stall. The function unit that
should be adding r3 and r5 together is instead sitting
idle, waiting for the load to complete so the add instruction can
be decoded and issued.
Out-of-order execution, or dynamic scheduling, is a technique used
to get back some of that wasted execution bandwidth. With out-of-order
execution (OoO for short), the processor would issue each of the
instructions in program order, and then enter a new pipeline stage called
"read operands" during which instructions whose operands are available would
move to the execution stage, regardless of their order in the program.
The term issue could be redefined at this point to mean "issue
and read operands."
Implementation of Out-of-order Execution
To implement an OoO processor, the pipeline has to be enhanced to keep
track of the extra complexity. For instance, now that we can reorder
instructions, we can have WAR and WAW hazards that we didn't have to worry
about with an inorder pipeline. This diagram illustrates the basic idea:
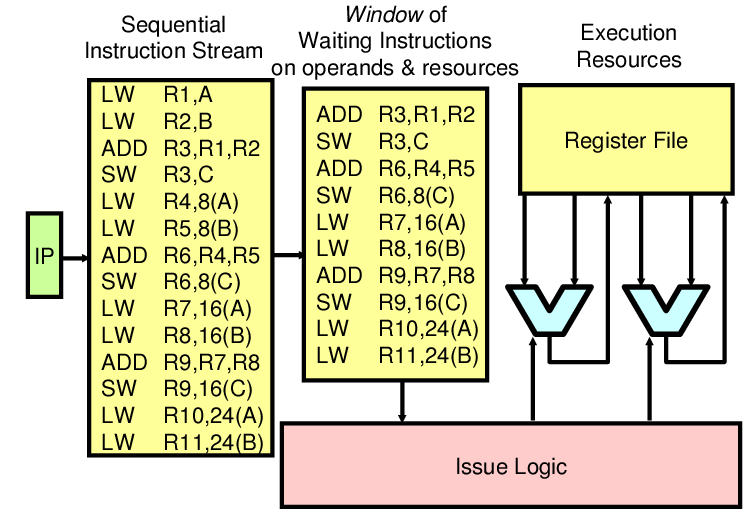
The following tricks are used:
- Register renaming. Registers that are the destinations of instruction
results are renamed, i.e., more than one version of that register name
may be used in the hardware. (This can be done in the compiler, but
only with architecturally visible registers; it is a much more powerful
technique when implemented in hardware.) This can be done in a new "rename
registers" pipeline stage that allocates physical (i.e. real) registers to
instances of logical (i.e. ISA) registers using a Register Alias Table,
that also keeps track of a "free list" of available physical registers.
Or, the renamed registers can be provided implicitly by using reservation
stations (or both). We'll talk about reservation stations for now.
- Instruction window. This buffer holds instructions that have been
fetched and decoded and are waiting to be executed. Note: Often,
the instruction window doesn't actually exist as a single buffer, but is
distributed among reservation stations (see below).
- Enhanced issue logic. The issue logic must be enhanced to issue
instructions out of order depending on their readiness to execute.
- Reservation stations. Each functional unit has a set of reservation
stations associated with it. Each station contains information about
instructions waiting or ready to issue. The reservation stations can also
be used as the physical mechanism behind register renaming.
- Load/store queue. This is like having reservation stations for the
memory unit, but with special properties to avoid data hazards through
memory.
- Scoreboarding or Tomasulo's Algorithm. These are algorithms that keeps
track of the details of the pipeline, deciding when and what to execute.
The scoreboard knows (or predicts) when results will be available from
instructions, so it knows when dependent instructions are able to be
executed, and when they can write their results into destination registers.
In Tomasulo's algorithm, reservation stations are used to implicitly
implement register renaming. (Other schemes add an actual physical register
file and Register Alias Table for doing renaming, allowing the new scheme
to eliminate more data hazards.)
- Common data bus (CDB). The common data bus is a network among the
functional units used to communicate things like operands and reservation
station tags.
The new pipeline is divided into three phases, each of which could take a
number of clock cycles:
(This stuff is all from Chapter 2)
- Issue:
- Fetch: The fetch unit keeps instructions in an instruction
queue, in program order (i.e., first-in-first-out). These
instructions are fetched with the assistance of branch prediction.
The issue phase dequeues an instruction from this queue.
- Decode. The instruction is decoded to determine what functional
units it will need.
- Allocate reservation station. If there is a reservation
station available at the function unit this instruction needs,
send it there; otherwise, stall this instruction only
because of the structural hazard.
- Read operands. If the operands for the instruction
are available, send them to the reservation station for that
instruction. Otherwise, send information about the source for
those operands to the reservation station, which will wait for
the operands. This information takes the form of tags
that name functional units and other reservation stations.
- Rename registers. Implicitly, by sending tags instead of
register names to the reservation stations, the issue phase renames
registers in a virtual set of registers. For example,
WAW hazards are no longer possible, since the same register in two
different instructions corresponds to two different reservation
stations.
- Execute. At the reservation station for this instruction, the following
actions may be taken:
- Wait for operands. If there are operands that haven't
been computed yet, wait for them to arrive before using the
functional unit. At this point, the instruction has been "issued"
with references to where the operands will come from, but without
the values.
- Receive operands. When a value becomes available from a dependent
instruction, place it in the reservation station.
- Compute. When all operands are present in the reservation
station, use the functional unit to compute the result of this
instruction. If more than one reservation station suddenly has
all of its operands available, the functional unit uses some
algorithm to choose which reservation station to compute first.
Note that we are exploiting ILP here; in the same clock cycle,
each functional unit can be independently executing an instruction
from its own set of reservation stations.
- Load/store. It doesn't really matter which reservation
station "fires" first unless the functional unit is the memory
unit, in which case loads and stores are executed in program order.
Loads and stores execute in two steps: compute the effective address
and use the memory unit. Loads can go as soon as the memory unit
becomes available. Stores, like other instructions with operand
values, wait for the value to become available before trying to
aquire the memory unit.
- Write result. Once the result of an executed instruction becomes
available, broadcast it over the CDB. Reservation stations that are
waiting for the result of this instruction may make forward progress.
During this phase, stores to memory are also executed.
Note that this scheme is non-speculative. Branch prediction is used to
fetch instructions, but instructions are not executed until all of their
dependences are satisfied, including control dependences. So, there
is no problem with instructions fetched down the wrong path; they are
never executed because they are discarded once their dependent branches
are executed.
Reservation Stations
You can think of the reservation stations as structures or records
in some program. Each functional unit might have several reservation
stations forming a sort of queue where instructions sit and wait to for
their operands to become available and for the functional unit to become
available. The components of a reservation station for an instruction
whose source inputs are Sj and Sk are:
- Op. The operation to perform. This code is specific to the functional
unit with which this reservation station is associated. For example,
the set of values of Op for an arithmetic/logic functional unit might be {
Add, Subtract, Negate, And, Or, Not }. For a memory unit, the set of values
might be { Load, Store }.
- Qj, Qk. These are the tags for the reservation stations that will
produce Sj and Sk, respectively. A value of zero indicates that the
corresponding source has already received its value from a reservation
station.
- Vj, Vk. These are the actual values of the source operands. A value
here is only valid if the corresponding Q entry is zero, indicating that
the source value has arrived.
- A. Holds the effective address for a load or store. Initially,
it might hold only the immediate field of the instruction, until the
effective address computation has occured (recall that loads and stores
execute in two steps: EA computation and using the memory unit).
- Busy. This boolean condition is True if the reservation station
is occupied, False if it is free.
In addition, each register in the physical register file has an entry,
Qi, that gives the tag of the reservation station holding the instruction
whose result should be stored into that register. If Qi is zero, then
the value in the register file is the actual value of that register, i.e.,
the register is not renamed at that point.
Example
Let's look at an example from the book, on page 99. Consider the following
code:
ld f6,34(r2) // f6 := memory at r2 + 34
ld f2,45(r3) // f2 := memory at r3 + 45
mul f0,f2,f4 // f0 := f2 * f4
sub f8,f2,f6 // f8 := f2 - f6
div f10,f0,f6 // f10 := f0 / f6
add f6,f8,f2 // f6 := f8 + f2
Let's look at what the reservation stations will look like once the
first load has completed. The second load has done its effective address
computation, but is still waiting to use the memory unit. Rather than
using numbers for the reservation station tags, we'll use a combination
of names and numbers, e.g., Add3.
Here is how the reservation stations would look:
Name Busy Op Vj Vk Qj Qk A
Load1 no
Load2 yes Load 45 + Regs[r3]
Add1 yes Sub Mem[34+Regs[r3]] Load2 0
Add2 yes Add Add1 Load2
Add3 no
Mult1 yes Mul Regs[f4] Load2
Mult2 yes Div Mem[34+Regs[r2]] Mult1
And here is how the Qi field for the floating point register file would look:
Field F0 F2 F4 F6 F8 F10 ...
Qi Mult1 Load2 Add2 Add1 Mult2