As the performance provided by networking technologies dramatically increases, solutions for high-performance fine-grained distributed computing start to emerge. Computing based on clusters, or on networks of workstations, greatly increases the performance of a variety of applications at low costs [1,2,3,4].
The performance of such clusters relies heavily on low communication latency. For example, applications on clusters frequently rely on reliable multicast protocols to disseminate the state of the computation and to manage the state of the system. These protocols typically involve several rounds of message exchanges, and so are very sensitive to communication latency. For example, it has been shown that the effect of latency on the performance of Microsoft's Cluster Server is severe enough that, without low-latency communication, its scalability is limited to 8 nodes [5].
Similarly, computation-intensive parallel programs are difficult to effectively port to networks of workstations because of the effort required to hide the communication latency.
In the past, communication latency was mainly due to insufficient network bandwidth and excessive protocol overhead in the host. With the significant increases in available network bandwidth and host computing power, latency in current systems is mostly caused at the network-host interface. In particular, context switches between kernel and user-level applications are burdensome.
A number of user-level network interface protocols have been proposed [6,7,8,9], which eliminate the kernel from the critical path between the application and the network interface card. While eliminating the kernel protocol stack from the message path on the host greatly reduces protocol processing latencies, significant sources of latency remain. User-level threads on the receiving host still suffer from scheduling latencies and context switch overhead. If thread invocation is part of a receive-reply loop, the sender may be unduly delayed by the latencies first at the receiver and then at the sender. Thus, many user-level protocols (for the case of user-level network interfaces, all protocols) that rely on any form of request-reply cycle between sender and receiver incur such delays at the interface between network interface card and user-level threads. Such protocols are very common in distributed computing, for example, reliable transmission, directory management and token-based mechanisms in general. Very often, the amount of computation at the receiver is trivial, typically involving some form of simple table lookup.
In this work, we propose to reduce latencies for user-level protocol processing by moving portions of the protocol-related computation into the network. The network infrastructure should support distributed applications by efficiently performing latency-critical portions of the protocol processing rather than placing the burden on the kernels or user-level applications. As the protocol requirements of distributed applications vary, the network support to such applications should be configurable. Components of protocol stacks should therefore dynamically be deployable into the network during application startup. The resulting paradigm is that of a Network-Level Application Interface for distributed applications: components within the network can be programmed at user-level to perform protocol-related computation on behalf of distributed user programs.
We investigate the feasibility of this approach in the project PANIC (Protocols Aboard Network Interface Cards), where we focus on network-level processing of user-level protocols at the boundary of the network. That is, the user-level protocol processing happens either in the host or in the network interface card (NIC). While NIC-level processing avoids the context-switch overheads in the host, it has other advantages as well: Many query or dissemination protocols (for example, directory look-ups or invalidation requests) rely on multicast communication schemes. These protocols cause unnecessary processing and interrupts at host level. Only one host in the multicast group may have the directory entry to be returned or invalidated, while all incur the overhead of passing the message to the application layer. Processing such requests within the network (that is, processing the directory management at the network level) not only significantly reduces the latency of directory look-ups, but significantly reduces the number of context switches on the host as well, as requests are effectively handled at network level before a host interrupt is generated.
Similarly, authentication and authorization checks for incoming messages in a distributed security framework can be done at network level, that is, before the message reaches the host. In this way, hosts can be effectively shielded from many forms of denial-of-service attacks.
Traditionally, NICs contain some amount of protocol processing in their firmware. Additional protocol components can therefore easily be embedded. The drawback of this method is that the NIC control program must be recompiled and re-installed whenever a significant change in protocol behavior is desired, however. Once the custom firmware is re-installed, its behavior is limited by hard-coded functionality.
The PANIC approach focuses on greater versatility. To achieve this, we incorporate a virtual machine (VM) for protocol processing into the NIC firmware. Protocol stacks, or portions thereof, can be dynamically deployed or recalled, or portions dynamically swapped at runtime. These operations can happen either on the local NIC or across the network on several NICs in an orchestrated fashion. A programming environment on the host allows us to define protocol components in a high-level language, PDL, which we specifically designed to support protocol processing. A compiler transforms PDL programs into loadable modules that are then interpreted by the virtual machine on the NIC. Protocol stacks are defined either as single PDL programs or as collections of inter-operating PDL programs.
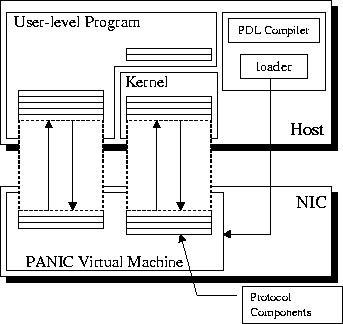
PANIC is specifically designed to augment the existing protocol processing on the card. In this spirit, it does not interfere with existing packet delivery mechanisms. At no point do the operations on the VM affect the execution of the remainder of the NIC control program. The structured communication between PANIC programs allows them to form a dynamic protocol stack or portions thereof, on the card. The complete protocol stack may reside entirely in the host, entirely in the card, or be split between the host and card as illustrated in Figure 1. The network designer chooses how to best distribute the burden of protocol processing. For example, in an authentication subsystem, the table lookups and simple hash operations for incoming requests could be easily performed within the NIC, while more expensive encryption operations would remain on the host. Similarly, preprocessing of outgoing video data in a distributed multimedia system would be done on the host, while the shaping and policing of the outgoing traffic would be performed on the NIC.
Communication between protocol components on the host and on the NIC happen through a message based interface or through shared memory. Appropriate lightweight synchronization mechanisms between host and NIC complete the host/NIC interface in PANIC.
Myrinet is a good candidate because of its readily modifiable, modular firmware, real-time clock, very low latency, and high data transfer rate. Myrinet's high performance is particular interesting in this context, as it exposes the limitations of the processing messages on the host particularly well. Myrinet is a network technology capable of transmitting 1.28 gigabits of data per second over fully duplex lines up to 8 meters, and half that rate for up to 25 meters. Sustained transfer rates are constrained by the inability of the host operating systems to process data at these speeds, and the low latencies provided by the network are countered by the protocol processing overhead on the host. Myrinet sprang from two DARPA sponsored projects - the Caltech Mosaic fine-grain multi-computer and the USC ATOMIC LAN project. Myrinet is specified at the data link and at the SAN and LAN physical levels as an American National Standard ANSI/VITA 26-1998.
A Myrinet network is composed of unique interfaces, switches, links, and software. Some of its salient features other than speed are an extremely low bit error rate, flexible topology, self-mapping, and the ability to carry virtually any type of packet.
In its current realization, PANIC executes protocol components on the Myrinet NIC within a virtual machine (VM). The first-generation VM is a simple stack machine that interprets code generated by the PDL compiler on the host which has two main parts: a loader to manage the memory used to store PANIC programs, and an interpreter to execute those programs.
The current realization of the VM is targeted towards simplicity rather than performance. Memory for PANIC programs is divided into instruction and data sections, both implemented as global arrays in the NIC SRAM. With few exceptions, memory in PANIC programs is static, and as such is allocated at load-time. The VM instruction set relies on relative addressing, making the code relocatable. Similarly, memory references are resolved relative to the beginning of the memory section allocated to the PANIC program. Program loading is very simple, and both code and memory segments can be relocated later by the loader to accommodate newly loaded programs.
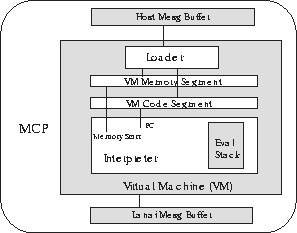
The interpreter is based on a stack machine. Instructions and data are pushed on the stack. As the instructions are popped from the stack, some invoke network services using data on the stack as parameters. Other instructions cause calculation of new values to be stored on the stack in a program's data section for later use. Figure 2 illustrates the overall design of the VM.
In order to quickly direct incoming packets for processing by the PANIC VM, they must be readily identifiable. In the Myrinet implementation we take advantage of a tagging mechanism used by the control program on the NIC to distinguish incoming control messages from data messages. We simply designate a new packet type, call it PANIC packet, that co-exists with other Myrinet packet types.
To cause minimal intrusion to normal packet processing on the host, we let PANIC packets be dispatched in the same fashion as all other incoming packets. Normal Myrinet behavior is unaffected except for the delay of executing the PANIC programs. Inasmuch as the Myrinet processor runs at a modest 25 MHz, these programs must be simple. For complex operations, the work is spread over two or more PANIC components, which each comprises a portion of the protocol stack. In this fashion, PDL programs temporarily relinquish control to the Myrinet firmware, and thus allow for some amount of multiprogramming on the card.
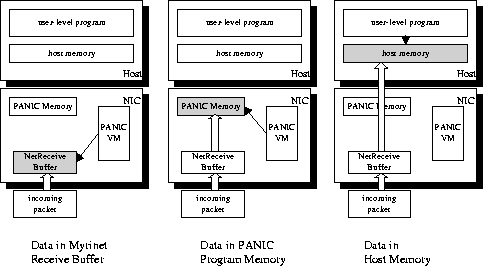
The PANIC VM demultiplexes incoming data in three distinct ways. For immediate short-term use, PANIC accesses variables directly in the NetReceive Buffer that holds the freshly arrived packet. No data movement is required for this method. For somewhat longer use, the PANIC VM may copy portions of an incoming packet to variables in its memory space. Lastly, the data may be moved, via DMA, into a reserved host buffer for access by a user application or, perhaps, another PANIC program. These three methods are illustrated in Figure 3.
In order for applications on the host and their programs within PANIC VMs to effectively interact, we provide a shared memory space between host and PANIC VM and mechanisms for efficient synchronization between processes and threads on the host and programs on the PANIC VM. In addition, an interface is in place to control the loading and activation of PANIC programs.
Program Management
A library and suite of tools to load, unload, run, and send messages to PANIC programs is supplied. These operations can control programs locally or on remote PANIC VMs and currently use programmed I/O rather than DMA to transfer data because the program messages typically are small.
Memory Management
We provide a shared memory space between the PANIC VM and user programs within a DMA-able memory segment allocated by the device driver on the host. Applications acquire segments of this memory through malloc/attach-style calls, which reserve segments for use. The application and the PANIC VM attach to the same memory segment by sharing its segment identifier. The shared memory paradigm is not fully supported here: while user programs access memory directly, the PANIC VM has to access it through DMA operations. When applications exit, they free the memory to restore it for general use.
Synchronization
Synchronization between host and NIC is based on a lock/flag model. The host may set locks and clear flags; the NIC may clear locks and set flags. The locking structure is in Shared Memory and may be protected with mutexes from the host side. There no interrupts involved. An application is expected to create a lightweight process to periodically check the flag that may be set by a PANIC program. Similarly, a PANIC program may check for a lock set by an application and take some appropriate action.
The host-network interface is realized through a library of functions residing on the host. This Panic API co-exists harmoniously with the two standard Myrinet libraries, libMyriApi and libMyriBpi. Panic API functions come in two flavors: those that directly access the memory mapped section of the NIC designated as Shared Memory, and those that use device driver assistance to communicate with the card.
PDL is a general purpose programming language created for this research project. Through modifications to the compiler, the language evolves to meet ever-changing demands. Figure 4 shows a sample PDL program, the "ping" program, which we use for latency measurements in the section on Performance.
PROGRAM PING: # -- This program initiates, awaits reply from remote program.
VAR timesent[100], timerec[100], i, msg[1024]; # -- Variable declarations
TRIGGERS 10; # -- Trigger declarations
BEGIN # -- Program Initialization
i = 0;
timesent[i] = CLOCK;
SEND msg[0] LEN 64 AS 12 TO 415 AT 0:0:0:96:221:127:255:140;
AWAIT; # -- Wait for first message to come in
END;
MESSAGE 10: # -- Trigger block for trigger 10
BEGIN
timerec[i] = CLOCK; i = i + 1;
if i < 100 THEN BEGIN
Timesent[i] = CLOCK;
SEND msg[0] LEN 64 AS 12 TO 415 AT 0:0:0:96:221:127:255:140;
AWAIT; # -- Wait for the next trigger to arrive
# -- We never reach this point
END;
i = 0; # -- Reach here when i >= 100
# -- Send timestamp information to buffer for reading by host
WHILE i < 100 DO BEGIN
DISPLAY timesent[i]; DISPLAY timerec[i]; i = i + 1;
END;
STOP;
END; # -- End of Trigger block
END; # -- End of program
Structure
PANIC programs begin with the keyword PROGRAM followed by a program identifier, which is used by the VM to reference to the program. Variable declarations are preceded by the keyword VAR followed by a variable list. Trigger declarations, prefaced by the keyword TRIGGERS, conclude the declarative portion of a PDL program. This is followed by a program initialization portion, and then by a number of trigger blocks. Trigger blocks, prefaced with the keyword MESSAGE, may contain one or one blocks of statements. Statements are formed from assignments, flow of control and arithmetic operators, and special statements.
Flow of Control
PDL is a sequential, top-down language. The top down flow may be broken by WHILE, IF, and MESSAGE statements. MESSAGE statements are blocks akin to function calls. Control passes to these blocks upon receipt of a PANIC message addressed to a trigger within the program. PANIC messages can arrive from the host, from another PANIC program within the same VM, or from across the network. Upon receiving a PANIC message, the VM demultiplexes it to the waiting destination trigger by looking up the program identifier and trigger identifier in the PANIC message header.
Special Statements
This class of statements target PDL for protocol processing within the PANIC framework. They support real-time clock access, send and receive operations to and from the network, and communication and synchronization with the user programs on the host.
The interpreter of the PANIC VM is a simple, stack based, machine, and its instruction set consists of general purpose instructions for program flow control, arithmetic and memory access operations. In addition, it directly supports the PDL special statements in its instruction set.
We performed two experiments to assess the performance of our PANIC VM. In the first experiment, we measured the message delivery latency between two VMs. For this, we preformed a series of message round-trip measurements in a ping-pong setting. In the second experiment, we focused on the VM-host interface and measured the data transfer latency from a VM to the host memory.
On a small network of Myrinet-connected hosts, we selected two, a Sparc-5 and Sparc T-1000 for the latency test. The hosts were connected by two Myricom 4-port switches (M2F-SW4) and Myricom LAN/SBus interfaces (M2F-SBus32A). Neither host is designated as the mapper in our topology. Both hosts were executing no other user applications besides the test suites.
mcp2mcp
The applications are a pair of PANIC programs, see Figure 4, running entirely on the Myrinet NIC. Timestamps were captured on the card using the PDL CLOCK function and the NIC's real-time clock register. Each CLOCK operation has an overhead of approximately 7 usecs. The test applications include the timestamp overhead, but exclude the time required to increment and compare the counter that determines the number of packets transmitted. Payload size excludes any header data, which is 16 bytes for all Myrinet packets and 16 bytes additionally for PANIC packets. For these tests, we send the uninitialized content of a PANIC variable to the second card, which returns that data. One hundred individual exchanges were performed, and the timestamps written to the LANAIMESGBUFF for reading by the host. The times used the to construct the graph are the mean of the 100 exchanges.
GetDeliver
These applications are also a pair of PANIC programs running entirely on the Myrinet NIC. However, the applications move, via DMA, the packet payload from host memory into a PANIC variable and send that variable to the second card. The receiver DMAs the payload into a reserved location in host memory. Immediately after that delivery completes, the data is DMA'd into a PANIC variable for returned to the first card. The host is not notified of the arrival or departure of the data. Times are taken on the card as in the mcp2mcp case.
api
This test uses Myricom's api_latency tool executing on the hosts to measure application-to-application round-trip times using a send-receive model that uses busy-polling to constantly check for an arrival packet. The tool reports the mean time for the number of exchanges specified using the Unix gettimeofday() function on the host. Because of high start-up costs associated with the tool, exchanges of fewer of 100 packets may not fully amortize this start-up delay. Each test therefore exchanged 100 packets. Although our PANIC mcp was installed, no component thereof was invoked by the test apps.
app2app
In this most complicated of the tests, an application on the host and PANIC program on the NIC co-operate in the exchange. The PDL program is identical to that in the GetDeliver test, except that the host is notified of packet delivery and re-transmission does not occur until the host initiates the action. Like the api_latency, the user-application employs busy-polling to detect changes in a lock signaling packet arrival. Times are measured on the host using gettimeofday(). Start-up times are excluded, thus allowing us to measure individual packet latencies rather than averaging as in the api_latency tests. Packets include a 16-byte MyriMesg header and a 16-byte PANIC header in addition to the payload.
The results of this series of measurements are illustrated in Figure 5. This figure depicts the packet round-trip latency as a function of exchange mechanism and packet size. Each point in the graph is the average of 100 measurements, where each measurement is the round-trip delay time for an individual packet of the specified size. The one exception to this measuring technique is in the api series. For that series, each point in the graph is the average of 100 experiments, where each experiment generates the average latency for 100 packet exchanges. Thus the api points are the mean of 10000 packet exchange times.
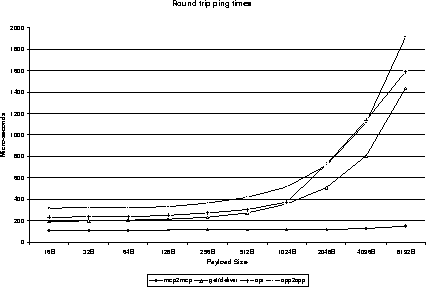
Our goal was not to improve Myrinet's overall performance. Other researchers have demonstrated that packet latencies can be reduced by as much as an order of magnitude over those inherent in a standard Myricom distribution [10,11]. Rather, we show that our PANIC subsystem causes little, if any, degradation to the system in which it is embedded. Our performance benefits will come from selectively processing some packets on the card instead of speedily moving all packets to the host.
As was expected, the mcp2mcp pings show the promise of limiting communication to the card. The difference between the GetDeliver and app2app curves exposes excessive delay in our host-to-card collaboration. A small part of this latency is from the host reading and resetting the lock used for notification. A larger portion, up to 48 msecs on each side, stems from a very inefficient messaging interface between the host and the NIC. We have designed strategies to minimize the latter overhead.
These experiments measured the time spent in different sections of our VM. We instrumented critical portions of the PANIC firmware on the NIC and extracted timing information in a number of experiments. The PDL program in Figure 6 with a single trigger block was loaded on the card from a Sparc-5 host. That trigger block contained a single DELIVER statement, which DMAs data from the PANIC VM memory to a previously allocated portion of memory on the host.
PROGRAM delivertest: # DELIVER and trigger test program
VAR y, msg[50];
TRIGGERS 10;
BEGIN
msg[0] = 2;
msg[1] = 3;
msg[2] = 4;
AWAIT
END;
MESSAGE 10: BEGIN
DELIVER msg[0] OFFSET 0 INTO 2 LEN 64;
AWAIT
END;
END;
The PANIC VM first determines whether the PANIC program to which a newly arrived message is addressed exists on the NIC. If so, control passes to the interpreter, which searches for a trigger block waiting for the message. If the specified trigger exists, the interpreter sets the program counter, ascertains the beginning of the memory segment for the program, and executes statements until a AWAIT is encountered. The two statements executed were DELIVER followed by an AWAIT. The DELIVER causes a DMA transfer from PANIC VM variable space into the specified segment in host memory. We break the DELIVER operation into two phases: time required for the VM to reach the DELIVER op code, and time required to complete the actual DMA. The small amount of time required to process the AWAIT is also included in the execution time of the interpreter.
The measurements of time spent in various components of the PANIC VM are shown graphically in Figure 7. Times shown are not cumulative; i.e., time shown for the interpreter is exclusive of the time spent in DELIVER and DMA. We performed the measurements 5 times for each payload size and report the average, The individual measurements were consistent throughout the tests, varying no more than a microsecond for any given operation, except, of course, the payload-sensitive DMA operation. Most of the time spent in the interpreter is attributable to start-up costs. Where, as here, we incurred those costs to execute a single non-trivial statement, the start-up cost is disproportionate to the work actually performed. Had we executed several statements, interpreter overhead would appear less burdensome.
The experiments reveal one obvious candidate for improvement - the interpreter - and a less obvious need for compiler modification. Execution of the interpreter is more costly than DMA movement of 512 bytes of data, Most of this latency is due to start-up costs that could be ameliorated over several statements; however, we are investigating ways to reduce this delay.
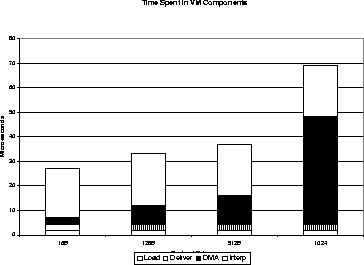
As the amount of data being moved via DMA increases, time required for the transfer increases linearly. For DMA movements of 1 kByte or more, time spent in the DMA machine dominates all other activities. In some circumstances the DMA must complete before program execution can continue. For example, if a program issues a GET command to load a local variable from host memory, then uses that variable in a computation, the DMA must finish before computation proceeds. In other situations, it would be possible to start the DMA and immediately resume execution of subsequent statements not dependent on the data transfer. We are exploring ways to make our compiler ßmart" so that it can detect and generate code to effectively handle data dependencies.
As noted, this work is the natural convergence of two distinct trends in network programming: Dynamic configuration of protocol stacks and user-level network interface protocols. Some of the salient work in each field is summarized below:
Researchers concur on the need to remove the OS from network messaging paths. A recent survey [16] reported eleven schemes to boost throughput and reduce latency. The common strategy is moving messages out of the network and into application memory with minimal OS intervention. These systems, loosely categorized as User Level Network Interface Protocols, report impressive delivery times. VIA, Virtual Interface Architecture [17], seems destined to become an industry standard.
Researchers also recognize the need to tailor protocol layers to application demands. Forcing every network message through a regimented kernel protocol stack is wasteful. As process requirements fluctuate, so too should messaging protocols. Advanced protocol design techniques include application-level framing, in which the protocol buffering is fully integrated with application-specific processing. Integrated layer processing, in which many protocol layers are collapsed into an efficient code path, is another alternative. Work in this area has led to dynamic protocol configuration in such well-known systems as X-Kernel [18], STREAMS [19], and DaCapo [20]. Ensemble uses formal verification technology to automatically generate optimized protocol stacks. Since this project was undertaken, two similar efforts have surfaced and are discussed herein. These two works demonstrate the feasibility of intelligent network devices while leaving open questions related to which tasks the devices should undertake and how to best implement those tasks.
Application-Specific Handlers [21], or ASHs, are user-written code fragments executed in the kernel when a network message arrives. ASHs offer three primary services: (i) they dynamically provide message vectoring; i.e., direct where messages are copied in memory, (ii) they reply to messages, and (iii) they perform general computation and control. These basic services lend themselves to higher level functionality in ASH systems. ASHs automatically perform integrated layer processing (ILP), whereby all operations on a message are combined in a single memory traversal. Dynamic composition of protocols in kernel space is accomplished by selective invocation of one or more handlers.
Historically, I/O interconnects have been much slower than the attached I/O devices. High performance network cards can saturate the bus used for host-card communication. Evolution of the personal computer from a desktop tool to an enterprise server is made possible by a standardized, intelligent I/O architecture known as I20 [22]. This architecture delegates much of the interrupt processing and hardware management to separate I/O processors (IOP). These IOPs may reside on the main board or the peripheral device itself. Each IOP runs its own embedded operating system tailored for the device. For example, Wind River's I20 real-time OS (IxWorks), has been ported to Intel's 960 Rx chips and DEC StrongARM I/O platform. IOP performance is limited only by processor speed and memory availability. Both these limitations are artificial and will yield to decreasing hardware cost.
SPINE [23] is touted as a Network Operating System. The SPINE runtime resides in the host kernel while SPINE extension written in Modula-3 are downloaded to a Myrinet network interface. As proof that the concept is viable, two applications - video server and IP router - are implemented with impressive results. This work demonstrates that network interfaces may indeed perform work heretofore left to the host.
A more general framework for an intelligent network device is U-NET/SLE reported by UC-Berkeley [24]. That work extends the U-Net model by incorporating a scaled-down JAVA Virtual Machine on a Myrinet network interface. JAVA applets are downloaded to the network interface to serve as Active Message style handlers for incoming/outgoing packets. Much empirical data is provided to justify the choice of JIVE (Java Implementation for Vertical Extensions) as the virtual machine on the interface. Aside from reporting simple ping times between JAVA applets, the paper suggests future applications.
Perhaps closest to our PANIC system is Active Messages [6]. AM and its successor, AM-II [10] , are based on placing control information in message headers which will invoke a user level handler routine. The handler will efficiently extract the message from the network to the sender-specified address in host memory. The message is detected either by polling or interrupt. Polling is likely the best choice inasmuch as waking a sleeping thread on Solaris requires nearly 100 microseconds. PANIC messages also include control information in message headers - specifically the numeric id of a PANIC component (protocol) and trigger block therein. The trigger block is analogous to a function call. The key difference is that the PANIC component is invoked on the NIC rather than host memory. Another difference is the variety of actions. A PANIC component may help direct the message to a specific user memory location, redistribute the message to other NIC's or hosts, or invoke another component in the protocol scheme.
Fast Messages [25] was the first software system to exploit the hidden potential of Myrinet hardware. FM messages contain a pointer to a sender-specified handler that consumes data at the destination. FM first implemented a host level return-to-sender protocol. Senders optimistically pump packets into the network while reserving buffer space in host memory. At the destination, packets may be returned for lack of buffer space or successfully received and acknowledged. This clever scheme resulted in a one-way latency of 37 microseconds for 128-byte packets. Subsequent enhancements including explicit polling reportedly reduced the round trip latency to an astounding 11 microseconds for smaller packets.
VMMC [26] - Virtual Memory-Mapped Communication - is yet another system for optimizing message delivery. In a rather complex set-up procedure, receiving processes export areas of their address space wherein they agree to accept incoming data. Sending processes import these remote buffers they will use as destinations for transferred data. When a message arrives at a Myrinet NIC, it is automatically transferred into the memory of the receiving process. No "receive" primitive is defined. Attaching notification to a message causes invocation of a user level handler function once the message is received. Incoming and outgoing page tables are kept in a specialized NIC control program. That control program maintains a virtual-to-physical two-way set associative TLB for each process using VMMC on a given node. One way latency of 9.8 microseconds is reported. As previously noted, the major cost is disabling of Myrinet's self-mapping ability.
BDM [27] - Bulldog Myrinet - is designed for reliability and versatility. It offers five packet-delivery protocols through a host library and customized Myrinet NIC control program. Those protocols range from completely unreliable to guaranteed ordered delivery. A host process ideally selects one of the protocols by choosing appropriate calls from the well-stocked API library. Different processes may implement different reliability protocols. Sophisticated buffer management on the host coupled with tracking message status on the NIC is the core of this system. BDM is the first Myrinet extension to provide a threaded NIC control program. It also serves to demonstrate the feasibility of sharing protocol processing between host and NIC.
Reliable multicast protocols often rely on token-passing mechanisms and simple queue management for message ordering in the receiver hosts. We plan on measuring the benefits of moving these components of the protocol into the NIC, thus relieving the host of burdensome context switches. Moreover, we can take advantage of mechanisms that are particularly well suited for very high-speed, low error-rate, networks, such as ``buffering on the link'' by returning messages to the sender for flow control.
To further illustrate the feasibility and the performance benefits of PANIC-style network-level protocols, we plan to implement a shared memory management tool, such as Treadmarks [14] or Quarks [15] in PANIC. A DSM system distributes memory pages across a group of remote hosts. As applications write to those pages, they must be marked invalid for other readers. Eventually, updated pages, or the differences in those pages, must be propagated to applications that attempt to access those invalid pages. Empirical evidence will be collected to compare the PANIC-based DSM system with a traditional host-based implementation.
1 Contact Info: Riccardo Bettati, Department of Computer Science, Texas A&M University, H.R. Bright Building, College Station, TX 77843-3112, phone +1 (409) 845-5469, fax: +1 (409) 847-8578, e-mail: bettati@cs.tamu.edu.